Node+Webpack

Node
- 官方对 Node.js 的定义
- Node.js 是一个基于V8 引擎的JavaScript 运行时环境
- 也就是说 Node.js 基于 V8 引擎来执行 JavaScript 的代码,但是不仅仅只有 V8 引擎
- 前面我们知道V8 可以嵌入到任何 C ++应用程序中,无论是Chrome 还是 Node.js,事实上都是嵌入了 V8 引擎来执行 JavaScript 代码
- 但是在 Chrome 浏览器中,还需要解析、渲染 HTML、CSS 等相关渲染引擎,另外还需要提供支持浏览器操作的 API、浏览器自己的事件循环等
- 另外,在 Node.js 中我们也需要进行一些额外的操作,比如文件系统读/写、网络 IO、加密、压缩解压文件等操作
Node 架构
我们来看一个单独的 Node.js 的架构图
- 我们编写的 JavaScript 代码会经过 V8 引擎,再通过 Node.js 的 Bindings,将任务放到 Libuv 的事件循环中
- libuv(Unicorn Velociraptor)是使用 C 语言编写的库
- libuv 提供了事件循环、文件系统读写、网络 IO、线程池等等内容


Node 的应用场景
目前前端开发的库都是以 node 包的形式进行管理
npm、yarn、pnpm 工具成为前端开发使用最多的工具
越来越多的公司使用 Node.js 作为 web 服务器开发、中间件、代理服务器
大量项目需要借助 Node.js 完成前后端渲染的同构应用
资深前端工程师需要为项目编写脚本工具
很多企业在使用 Electron 来开发桌面应用程序
Node 程序传递参数
正常情况下执行一个 node 程序,直接跟上我们对应的文件即可
- node index.js
但是,在某些情况下执行 node 程序的过程中,我们可能希望给 node 传递一些参数
- node index.js env=development 开发环境
如果我们这样来使用程序,就意味着我们需要在程序中获取到传递的参数
- 获取参数其实是在process 的内置对象中的
- 如果我们直接打印这个内置对象,它里面包含特别的信息
- 其他的一些信息,比如版本、操作系统等
现在,我们先找到其中的 argv 属性
- 我们发现它是一个数组,里面包含了我们需要的参数
1
2console.log(process.argv);
// ['C:\\Program Files\\nodejs\\node.exe', 'G:\\index.js', 'env=development', '开发环境'],
为什么叫 argv 呢?
- 你可能有个疑问,为什么叫 argv 呢?
- 在 C/C++程序中的 main 函数中,实际上可以获取到两个参数
- argc:argument counter 的缩写,传递参数的个数
- argv:argument vector(向量、矢量)的缩写,传入的具体参数
- vector 翻译过来是矢量的意思,在程序中表示的是一种数据结构
- 在 C++、Java 中都有这种数据结构,是一种数组结构
- 在 JavaScript 中也是一个数组,里面存储一些参数信息
常见的全局对象
- process 对象:process 提供了Node 进程中相关的信息
- 比如 Node 的运行环境、参数信息等
- console 对象:提供了简单的调试控制台
- 更加详细的查看官网文档:https://nodejs.org/api/console.html
- 定时器函数:在 Node 中使用定时器有好几种方式
- setTimeout(callback, delay[, …args]):callback 在 delay 毫秒后执行一次
- setInterval(callback, delay[, …args]):callback 每 delay 毫秒重复执行一次
- setImmediate(callback[, …args]):callbackI / O 事件后的回调的 “立即” 执行
- process.nextTick(callback[, …args]):添加到下一次 tick 队列中
特殊的全局对象
- 为什么我称之为特殊的全局对象呢?
- 这些全局对象实际上是模块中的变量,只是每个模块都有,看来像是全局变量
- 在命令行交互中是不可以使用的
- 包括:
__dirname、__filename、exports、module、require()
__dirname:获取当前文件所在的路径- 注意:不包括后面的文件名
__filename:获取当前文件所在的路径和文件名称- 注意:包括后面的文件名称
JavaScript 模块化开发
什么是模块化?
到底什么是模块化、模块化开发呢?
- 事实上模块化最终的目的是将程序划分成一个个小的模块
- 这个模块中编写属于自己的逻辑代码,有自己的作用域,定义变量名词时不会影响到其他的模块
- 这个模块可以将自己希望暴露的变量、函数、对象等导出给其他的模块
- 也可以通过某种方式,导入其他模块中的变量、函数、对象等
按照这种模块划分开发程序的过程,就是模块化开发的过程
对于早期的 JavaScript 没有模块化来说,确确实实带来了很多的问题
模块化的历史
- 在网页开发的早期,Brendan Eich 开发 JavaScript 仅仅作为一种脚本语言,做一些简单的表单验证或动画实现等,那个时候代码还是很少的
- 这个时候我们只需要讲 JavaScript 代码写到
<script>标签中即可 - 并没有必要放到多个文件中来编写,甚至流行:通常来说 JavaScript 程序的长度只有一行
- 这个时候我们只需要讲 JavaScript 代码写到
- 但是随着前端和 JavaScript 的快速发展,JavaScript 代码变得越来越复杂了
- Ajax 的出现,前后端开发分离,意味着后端返回数据后,我们需要通过JavaScript 进行前端页面的渲染;
- SPA 的出现,前端页面变得更加复杂:包括前端路由、状态管理等等一系列复杂的需求需要通过 JavaScript 来实现
- 包括 Node 的实现,JavaScript 编写复杂的后端程序,没有模块化是致命的硬伤
- 所以,模块化已经是 JavaScript 一个非常迫切的需求
- 但是 JavaScript 本身,直到ES6(2015)才推出了自己的模块化方案
- 在此之前,为了让 JavaScript 支持模块化,涌现出了很多不同的模块化规范:AMD、CMD、CommonJS等
没有模块化带来的问题
早期没有模块化带来了很多的问题:比如命名冲突的问题
当然我们有办法可以解决上面的问题:立即函数调用表达式(IIFE)
1
2
3
4
5
6
7
8
9
10
11
12
13
14<!--
aaa.js
const moduleA = (function() {
let name = "张三"
return { name }
}())
-->
<!--index.html-->
<script src="./aaa.js"></script>
<script>
console.log(moduleA.name);
</script>但是我们其实带来了新的问题
- 第一:我必须记得每一个模块中返回对象的命名,才能在其他模块使用过程中正确的使用
- 第二:代码写起来混乱不堪,每个文件中的代码都需要包裹在一个匿名函数中来编写
- 第三:在没有合适的规范情况下,每个人、每个公司都可能会任意命名、甚至出现模块名称相同的情况
虽然实现了模块化,但是我们的实现过于简单,并且是没有规范的
- 我们需要制定一定的规范来约束每个人都按照这个规范去编写模块化的代码
- 这个规范中应该包括核心功能:模块本身可以导出暴露的属性,模块又可以导入自己需要的属性
- JavaScript 社区为了解决上面的问题,涌现出一系列好用的规范,接下来我们就学习具有代表性的一些规范
CommonJS
我们需要知道 CommonJS 是一个规范,最初提出来是在浏览器以外的地方使用,并且当时被命名为ServerJS,后来为了体现它的广泛性,修改为CommonJS,平时我们也会简称为 CJS
- Node是 CommonJS 在服务器端一个具有代表性的实现
- Browserify是 CommonJS 在浏览器中的一种实现
- webpack 打包工具具备对 CommonJS 的支持和转换
所以 Node 中对CommonJS 进行了支持和实现,让我们在开发 node 的过程中可以方便的进行模块化开发
- 在 Node 中每一个 js 文件都是一个单独的模块
- 这个模块中包括CommonJS 规范的核心变量:exports、module.exports、require
- 我们可以使用这些变量来方便的进行模块化开发
前面我们提到过模块化的核心是导出和导入,Node 中对其进行了实现
- exports 和 module.exports可以负责对模块中的内容进行导出
- require 函数可以帮助我们导入其他模块(自定义模块、系统模块、第三方库模块)中的内容
1
2
3
4
5
6
7
8
9
10
11
12// util.js
const UTIL_NAME = "util_name";
function formatDate() {
return "2022-10-10";
}
exports.UTIL_NAME = UTIL_NAME;
exports.formatDate = formatDate;
// main.js
const { UTIL_NAME, formatDate } = require("./util.js");
console.log(UTIL_NAME); // util_name
console.log(formatDate()); // 2022-10-10
exports
exports 是一个对象,我们可以在这个对象中添加很多个属性,添加的属性会导出
1
2
3
4
5
6
7// bar.js
exports.name = "张三";
exports.age = 18;
setTimeout(() => {
console.log("bar", exports); // bar { name: '李四', age: 20 }
}, 2000);在另外一个文件中可以导入
1
2
3
4
5
6// main.js
const bar = require("./bar.js");
console.log("main", bar); // main { name: '张三', age: 18 }
bar.name = "李四";
bar.age = 20;上面这行完成了什么操作呢?理解下面这句话,Node 中的模块化一目了然
- 意味着 main.js 中的bar 变量等于 exports 对象
- 也就是 require 通过各种查找方式,最终找到了 exports 这个对象
- 并且将这个exports 对象赋值给了 bar 变量(引用赋值)
module.exports
但是 Node 中我们经常导出东西的时候,又是通过 module.exports 导出的
- module.exports和exports有什么关系或者区别呢
我们追根溯源,通过维基百科中对 CommonJS 规范的解释
- CommonJS 中是没有module.exports的概念的
- 但是为了实现模块的导出,Node 中使用的是Module 的类,每一个模块都是 Module 的一个实例,也就是 module
- 所以在 Node 中真正用于导出的其实根本不是 exports,而是module.exports
- 因为module 才是导出的真正实现者
但是,为什么 exports 也可以导出呢?
- 这是因为module 对象的 exports 属性和 exports 对象默认指向同一个对象
1
2
3
4
5
6
7
8
9
10// bar.js
// 默认情况下 module.exports 和 exports 指向同一个对象
console.log(module.exports === exports); // true
module.exports = { name: "module.exports" };
exports.name = "exports";
// main.js
const bar = require("./bar.js"); // 导入 module.exports 导出的对象
console.log(bar.name); // module.exports
require
我们现在已经知道,require 是一个函数,可以帮助我们引入一个文件(模块)中导出的对象
那么,require 的查找规则是怎么样的呢?
这里我总结比较常见的查找规则
导入格式如下:require(X)
情况一:X 是一个 Node 核心模块,比如 path、http
- 直接返回核心模块,并且停止查找
1
2const path = require("path");
console.log(path); // {...}情况二:X 是以 ./ 或 …/ 或 /(根目录)开头的
第一步:将 X 当做一个文件在对应的目录下查找
如果有后缀名,按照后缀名的格式查找对应的文件
如果没有后缀名,会按照如下顺序
- 直接查找文件 X
- 查找 X.js 文件
- 查找 X.json 文件
- 查找 X.node 文件
1
2
3
4
5
6
7
8
9
10
11
12
13// 结果一
// utils.js
module.exports = { info: "utils.js-文件" };
// main.js
const utils = require("./utils.js");
console.log(utils); // { info: 'utils.js-文件' }
// 结果二
// utils
module.exports = { info: "utils-文件" };
// main.js
const utils = require("./utils");
console.log(utils); // { info: 'utils-文件' }- 第二步:没有找到对应的文件,将 X 作为一个目录
- 查找目录下面的 index 文件
- 查找 X/index.js 文件
- 查找 X/index.json 文件
- 查找 X/index.node 文件
- 查找目录下面的 index 文件
- 如果没有找到,那么报错:not found
1
2
3
4
5// utils/index.js
module.exports = { info: "index.js-文件" };
// main.js
const utils = require("./utils");
console.log(utils); // { info: 'index.js-文件' }情况三:直接是一个 X(没有路径),并且 X 不是一个核心模块
- 它会在当前文件夹的 node_modules 里面找,当前文件夹没找到就 往上找,如果在根目录还没找到就返回 not found
1
2
3
4
5
6// node_modules/axios/index.js
module.exports = { name: "axios" };
// main.js
const axios = require("axios");
console.log(process.mainModule.paths); // 查找方式
console.log(axios); // { name: 'axios' }
模块的加载过程
结论一:模块在被第一次引入时,模块中的 js 代码会被运行一次
结论二:模块被多次引入时,会缓存,最终只加载(运行)一次
- 为什么只会加载运行一次呢?
- 这是因为每个模块对象 module 都有一个属性 loaded
- 为 false 表示还没有加载,为 true 表示已经加载
结论三:如果有循环引入,那么加载顺序是什么
graph TD; main-->aaa-->ccc-->ddd-->eee; main-->bbb-->ccc; bbb-->eee;
- 这个其实是一种数据结构:图结构
- 图结构在遍历的过程中,有深度优先搜索(DFS, depth first search)和广度优先搜索(BFS, breadth first search)
- Node 采用的是深度优先算法:main -> aaa -> ccc -> ddd -> eee -> bbb
CommonJS 规范缺点
- CommonJS 加载模块是同步的
- 同步的意味着只有等到对应的模块加载完毕,当前模块中的内容才能被运行
- 这个在服务器不会有什么问题,因为服务器加载的 js 文件都是本地文件,加载速度非常快
- 如果将它应用于浏览器呢?
- 浏览器加载 js 文件需要先从服务器将文件下载下来,之后再加载运行
- 那么采用同步的就意味着后续的 js 代码都无法正常运行,即使是一些简单的 DOM 操作
- 所以在浏览器中,我们通常不使用 CommonJS 规范
- 当然在 webpack 中使用 CommonJS 是另外一回事
- 因为它会将我们的代码转成浏览器可以直接执行的代码
- 在早期为了可以在浏览器中使用模块化,通常会采用 AMD 或 CMD
- 但是目前一方面现代的浏览器已经支持 ES Modules,另一方面借助于 webpack 等工具可以实现对 CommonJS 或者 ES Module 代码的转换
- AMD 和 CMD 已经使用非常少了
AMD 规范
- AMD 主要是应用于浏览器的一种模块化规范
- AMD 是Asynchronous Module Definition(异步模块定义)的缩写
- 它采用的是异步加载模块
- 事实上 AMD 的规范还要早于 CommonJS,但是 CommonJS 目前依然在被使用,而 AMD 使用的较少了
- 我们提到过,规范只是定义代码的应该如何去编写,只有有了具体的实现才能被应用
- AMD 实现的比较常用的库是require.js 和 curl.js
CMD 规范
- CMD 规范也是应用于浏览器的一种模块化规范
- CMD 是Common Module Definition(通用模块定义)的缩写
- 它也采用的也是异步加载模块,但是它将 CommonJS 的优点吸收了过来
- 但是目前 CMD 使用也非常少了
- CMD 也有自己比较优秀的实现方案
- SeaJS
认识 ES Module
JavaScript 没有模块化一直是它的痛点,所以才会产生我们前面学习的社区规范:CommonJS、AMD、CMD 等,所以在 ECMA 推出自己的模块化时,大家也是兴奋异常
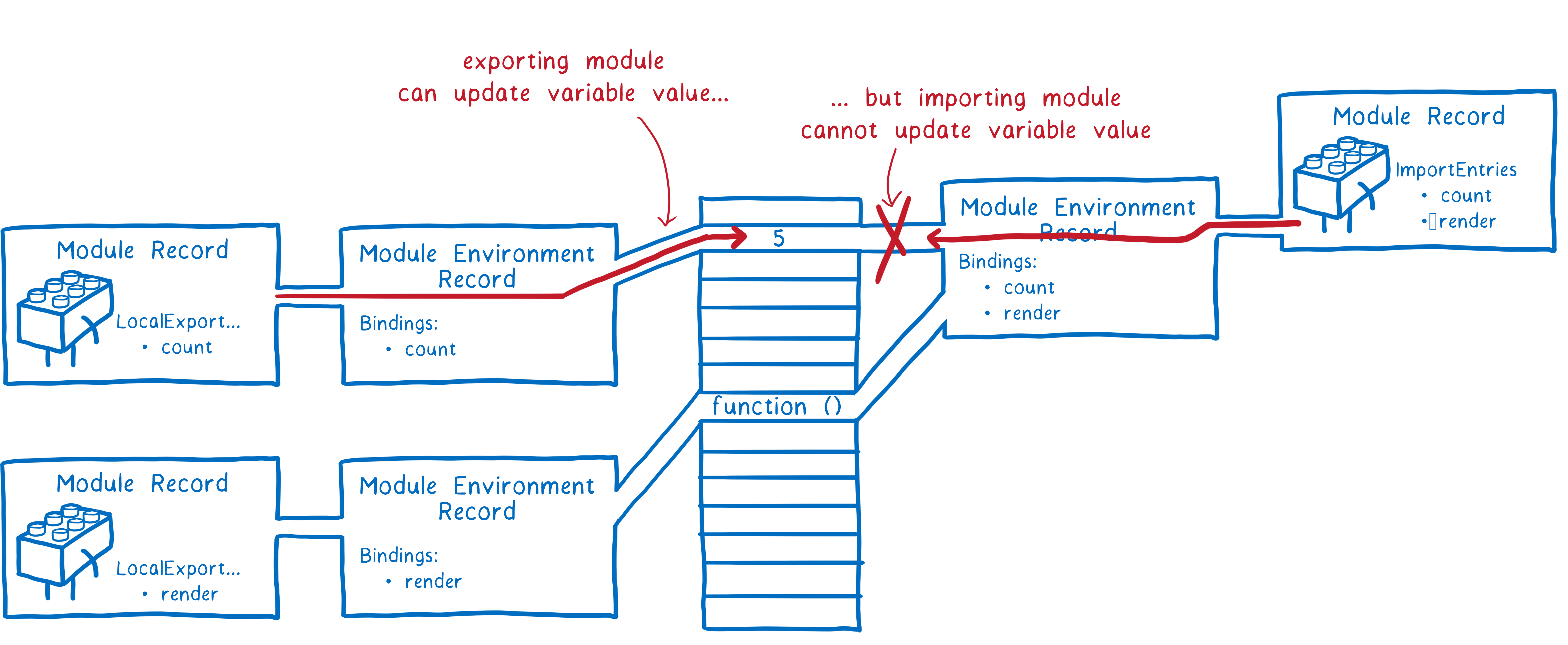
ES Module 和 CommonJS 的模块化有一些不同之处
- 一方面它使用了import和export关键字
- 另一方面它采用编译期的静态分析,并且也加入了动态引用的方式
ES Module 模块采用 export 和 import 关键字来实现模块化
- export负责将模块内的内容导出
- import负责从其他模块导入内容
了解:采用 ES Module 将自动采用严格模式:use strict
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// foo.js
const name = "张三";
function sayHello() {
console.log("say Hello");
}
export { name, sayHello };
// main.js
// 注意事项一: 在浏览器中直接使用esmodule时, 必须在文件后加上后缀名.js
import { name, sayHello } from "./foo.js";
console.log(name);
sayHello();
// index.html
// 注意事项二: 在我们打开对应的html时, 如果html中有使用模块化的代码, 那么必须开启一个服务来打开
// 你需要注意本地测试 -- 如果你通过本地加载 HTML 文件 (比如一个 file:// 路径的文件), 你将会遇到 CORS 错误,因为 JavaScript 模块安全性需要。你需要通过一个服务器来测试。MDN 对它的解释 https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Guide/Modules
<script src="./foo.js" type="module"></script>
<script src="./main.js" type="module"></script>
export
export 关键字将一个模块中的变量、函数、类等导出
我们希望将其他中内容全部导出,它可以有如下的方式
- 方式一:在语句声明的前面直接加上 export 关键字
1
2
3
4
5
6
7
8// foo.js
export const name = "张三";
export function sayHello() {
console.log("say Hello");
}
// main.js
import { name, sayHello } from "./foo.js";- 方式二:将所有需要导出的标识符,放到 export 后面的 {} 中
- 注意:这里的 {} 里面不是 ES6 的对象字面量的增强写法,{} 也不是表示一个对象的
- 所以:export {name: name},是错误的写法
1
2
3
4
5
6
7
8
9
10// foo.js
const name = "张三";
function sayHello() {
console.log("say Hello");
}
export { name, sayHello };
// main.js
import { name, sayHello } from "./foo.js";- 方式三:导出时给标识符起一个别名
- 通过 as 关键字起别名
1
2
3
4
5
6
7
8
9
10// foo.js
const name = "张三";
function sayHello() {
console.log("say Hello");
}
export { name as fName, sayHello };
// main.js
import { fName, sayHello } from "./foo.js";
import
import 关键字负责从另外一个模块中导入内容
导入内容的方式也有多种
- 方式一:import {标识符列表} from ‘模块’
- 注意:这里的 {} 也不是一个对象,里面只是存放导入的标识符列表内容
1
2
3
4
5
6
7
8
9
10// foo.js
const name = "张三";
function sayHello() {
console.log("say Hello");
}
export { name, sayHello };
// main.js
import { name, sayHello } from "./foo.js";- 方式二:导入时给标识符起别名
- 通过 as 关键字起别名
1
2
3
4
5
6
7
8
9
10// foo.js
const name = "张三";
function sayHello() {
console.log("say Hello");
}
export { name, sayHello };
// main.js
import { name as mName, sayHello } from "./foo.js";- 方式三:通过 * 将模块功能放到一个模块功能对象上
1
2
3
4
5
6
7
8
9
10// foo.js
const name = "张三";
function sayHello() {
console.log("say Hello");
}
export { name, sayHello };
// main.js
import * as foo from "./foo.js";- 方式一:import {标识符列表} from ‘模块’
export、import 结合使用
补充:export 和 import 可以结合使用
为什么要这样做呢?
- 在开发和封装一个功能库时,通常我们希望将暴露的所有接口放到一个文件中
- 这样方便指定统一的接口规范,也方便阅读
- 这个时候,我们就可以使用 export 和 import 结合使用
1
2
3
4
5
6
7
8// utils/index.js
// 优化一
export { formatCount, formatDate } from "./format.js";
export { parseLyric } from "./parse.js";
// 优化二
export * from "./format.js";
export * from "./parse.js";
default
前面我们学习的导出功能都是有名字的导出(named exports)
- 在导出 export 时指定了名字
- 在导入 import 时需要知道具体的名字
还有一种导出叫做默认导出(default export)
默认导出 export 时可以不需要指定名字
在导入时不需要使用 {},并且可以自己来指定名字
它也方便我们和现有的 CommonJS 等规范相互操作
注意:在一个模块中,只能有一个默认导出(default export)
1
2
3
4
5
6
7// parse.js
export default function () {
return ["歌词"];
}
// main.js
import geci from "./parse.js";
import()
通过 import 加载一个模块,是不可以在其放到逻辑代码中的,比如
1
2
3
4
5if (true) {
import { name, sayHello } from "./foo.js";
console.log(name, age);
}
// Cannot use import statement outside a module为什么会出现这个情况呢?
- 这是因为ES Module 在被 JS 引擎解析时,就必须知道它的依赖关系
- 由于这个时候 js 代码没有任何的运行,所以无法在进行类似于 if 判断中根据代码的执行情况
- 甚至拼接路径的写法也是错误的:因为我们必须到运行时能确定 path 的值
但是某些情况下,我们确确实实希望动态的来加载某一个模块
- 如果根据不懂的条件,动态来选择加载模块的路径
- 这个时候我们需要使用 import() 函数来动态加载
- import 函数返回一个 Promise,可以通过 then 获取结果
1
2
3
4
5
6
7
8
9if (true) {
import("./foo.js").then((res) => {
console.log(res);
});
} else {
import("./bar.js").then((res) => {
console.log(res);
});
}
import meta
import.meta 是一个给 JavaScript 模块暴露特定上下文的元数据属性的对象
- 它包含了这个模块的信息,比如说这个模块的 URL
- 在 ES11(ES2020)中新增的特性
1
console.log(import.meta);
解析流程
ES Module 是如何被浏览器解析并且让模块之间可以相互引用的呢?
ES Module 的解析过程可以划分为三个阶段
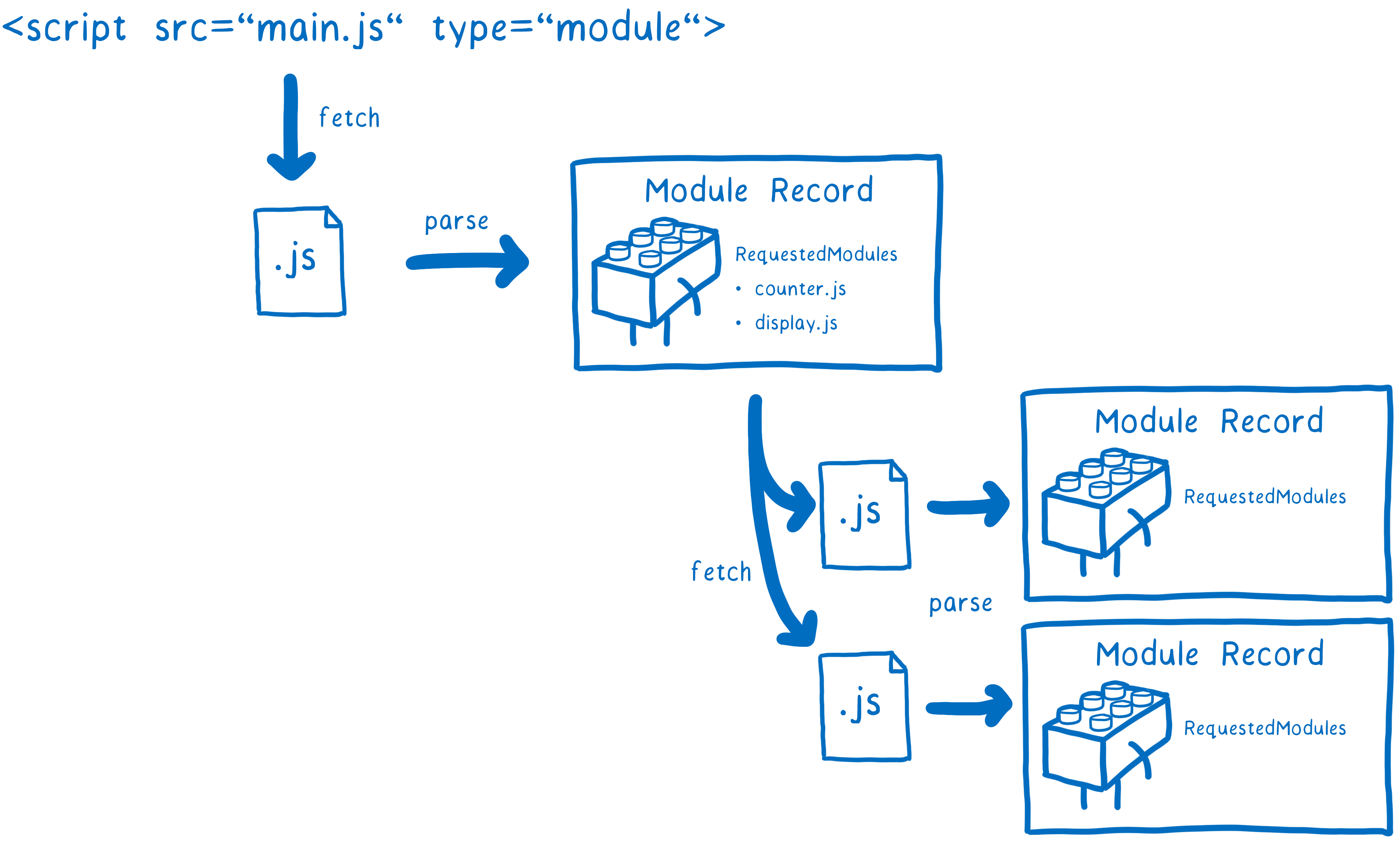
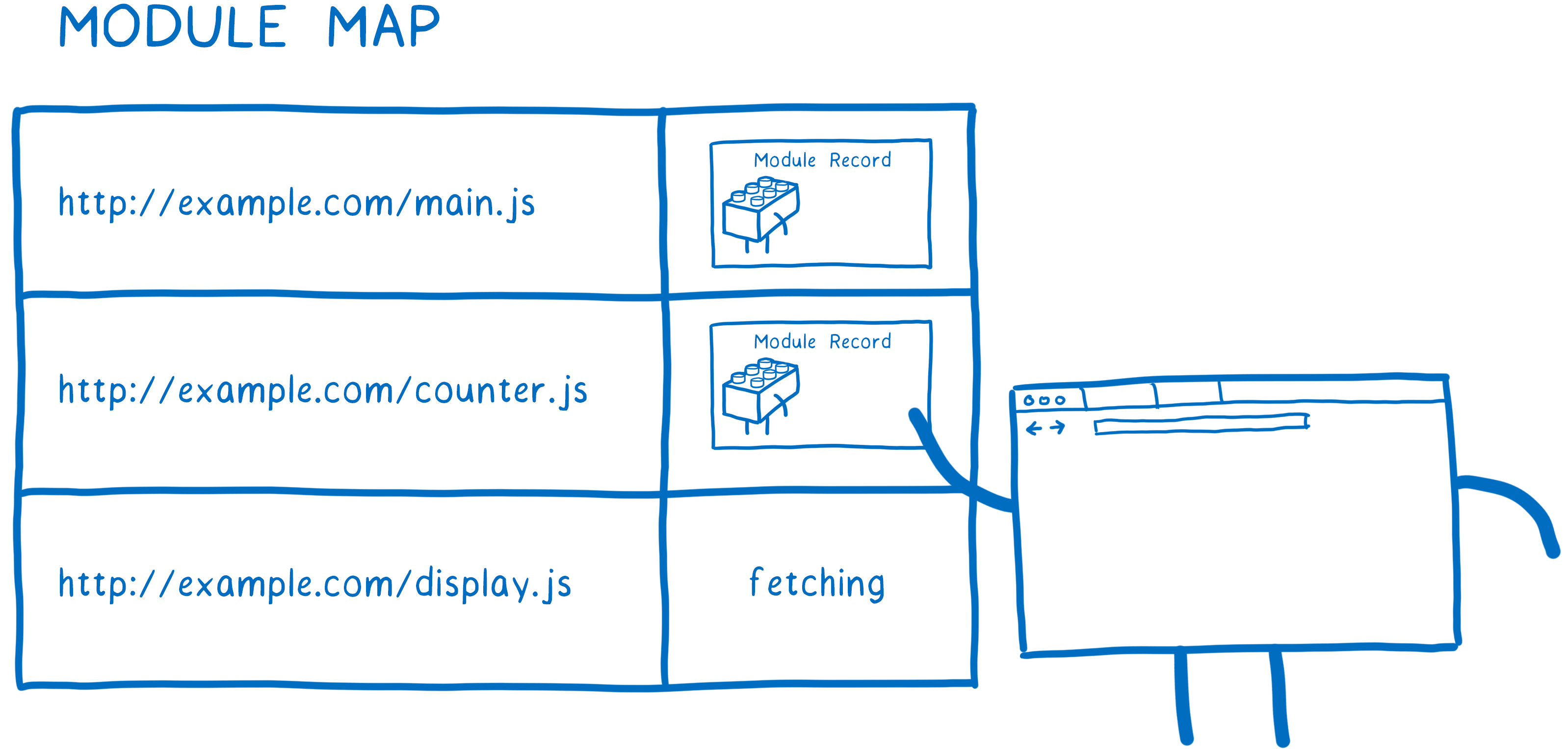
阶段一:构建(Construction),根据地址查找 js 文件,并且下载,将其解析成模块记录(Module Record)
阶段二:实例化(Instantiation),对模块记录进行实例化,并且分配内存空间,解析模块的导入和导出语句,把模块指向对应的内存地址
阶段三:运行(Evaluation),运行代码,计算值,并且将值填充到内存地址中
前端包管理工具
代码共享方案
- 我们已经学习了在 JavaScript 中可以通过模块化的方式将代码划分成一个个小的模块
- 在以后的开发中我们就可以通过模块化的方式来封装自己的代码,并且封装成一个工具
- 这个工具我们可以让同事通过导入的方式来使用,甚至你可以分享给世界各地的程序员来使用
- 如果我们分享给世界上所有的程序员使用,有哪些方式呢?
- 方式一:上传到 GitHub 上、其他程序员通过 GitHub 下载我们的代码手动的引用
- 缺点是大家必须知道你的代码 GitHub 的地址,并且从 GitHub 上手动下载
- 需要在自己的项目中手动的引用,并且管理相关的依赖
- 不需要使用的时候,需要手动来删除相关的依赖
- 当遇到版本升级或者切换时,需要重复上面的操作
- 显然,上面的方式是有效的,但是这种传统的方式非常麻烦,并且容易出错
- 方式二:使用一个专业的工具来管理我们的代码
- 我们通过工具将代码发布到特定的位置
- 其他程序员直接通过工具来安装、升级、删除我们的工具代码
- 显然,通过第二种方式我们可以更好的管理自己的工具包,其他人也可以更好的使用我们的工具包
npm
Node Package Manager,也就是Node 包管理器
但是目前已经不仅仅是 Node 包管理器了,在前端项目中我们也在使用它来管理依赖的包
比如 vue、vue-router、vuex、express、koa、react、react-dom、axios、babel、webpack 等等
如何下载和安装 npm 工具呢?
- npm 属于 node 的一个管理工具,所以我们需要先安装 Node
- node 管理工具:https://nodejs.org/en 安装 Node 的过程会自动安装 npm 工具
npm 管理的包可以在哪里查看、搜索呢?
- https://www.npmjs.org
- 这是我们安装相关的npm 包的官网
npm 管理的包存放在哪里呢?
- 我们发布自己的包其实是发布到 registry上面的
- 当我们安装一个包时其实是从 registry 上面下载的包
配置文件
- 那么对于一个项目来说,我们如何使用npm 来管理这么多包呢?
- 事实上,我们每一个项目都会有一个对应的配置文件,无论是前端项目(Vue、React)还是后端项目(Node)
- 这个配置文件会记录着你项目的名称、版本号、项目描述等
- 也会记录着你项目所依赖的其他库的信息和依赖库的版本号
- 这个配置文件就是package.json
- 那么这个配置文件如何得到呢?
- 方式一:手动从零创建项目,npm init –y
- 方式二:通过脚手架创建项目,脚手架会帮助我们生成 package.json,并且里面有相关的配置
常见的配置文件属性
必须填写的属性:name、version
- name是项目的名称
- version是当前项目的版本号
- description是描述信息,很多时候是作为项目的基本描述
- author是作者相关信息(发布时用到)
- license是开源协议(发布时用到)
private 属性
- private属性记录当前的项目是否是私有的
- 当值为 true 时,npm 是不能发布它的,这是防止私有项目或模块发布出去的方式
main 属性
- 设置程序的入口
- 比如我们使用 axios 模块 const axios = require(‘axios’)
- 如果有 main 属性,实际上是找到对应的 main 属性查找文件的
scripts 属性
- scripts 属性用于配置一些脚本命令,以键值对的形式存在
- 配置后我们可以通过 npm run 命令的 key 来执行这个命令
- npm start 和 npm run start 的区别是什么?
- 它们是等价的,对于常用的 start、 test、stop、restart 可以省略掉 run 直接通过 npm start 等方式运行
dependencies 属性
- dependencies 属性是指定无论开发环境还是生成环境都需要依赖的包
- 通常是我们项目实际开发用到的一些库模块 vue、vuex、vue-router、react、react-dom、axios等等
devDependencies 属性
- 一些包在生成环境是不需要的,比如 webpack、babel等
- 这个时候我们会通过 npm install webpack --save-dev,将它安装到 devDependencies 属性中
peerDependencies 属性
- 还有一种项目依赖关系是对等依赖,也就是你依赖的一个包,它必须是以另外一个宿主包为前提的
- 比如 element-plus 是依赖于 vue3 的,ant design 是依赖于 react、react-dom
依赖的版本管理
我们会发现安装的依赖版本出现:^2.0.3 或~2.0.3,这是什么意思呢?
npm 的包通常需要遵从 semver 版本规范
semver 版本规范是 X.Y.Z
- X 主版本号(major):当你做了不兼容的 API 修改(可能不兼容之前的版本)
- Y 次版本号(minor):当你做了向下兼容的功能性新增(新功能增加,但是兼容之前的版本)
- Z 修订号(patch):当你做了向下兼容的问题修正(没有新功能,修复了之前版本的 bug)
^和~的区别
- x.y.z:表示一个明确的版本号
- ^x.y.z:表示x 是保持不变的,y 和 z 永远安装最新的版本
- ~x.y.z:表示x 和 y 保持不变的,z 永远安装最新的版本
npm install 命令
- 安装 npm 包分两种情况
- 全局安装: npm install webpack -g
- 局部安装: npm install webpack
- 全局安装
- 全局安装是直接将某个包安装到全局
- 比如全局安装 yarn
- npm install yarn -g
- 但是很多人对全局安装有一些误会
- 通常使用npm 全局安装的包都是一些工具包:yarn、webpack 等
- 并不是类似于 axios、express、koa 等库文件
- 所以全局安装了之后并不能让我们在所有的项目中使用 axios 等库
项目安装
项目安装会在当前目录下生成一个 node_modules 文件夹,我们之前讲解 require 查找顺序时有讲解过这个包在什么情况下被查找
局部安装分为开发时依赖和生产时依赖
1
2
3
4
5
6
7
8
9
10
11# 默认安装开发和生产依赖
npm install axios
npm i axios
# 开发依赖
npm install webpack --save-dev
npm install webpack -D
npm i webpack –D
# 根据package.json中的依赖包
npm install
npm install 原理
执行 npm install 它背后帮助我们完成了什么操作?
我们会发现还有一个称之为package-lock.json 的文件,它的作用是什么?
从 npm5 开始,npm 支持缓存策略(来自 yarn 的压力),缓存有什么作用呢?
npm install 会检测是有 package-lock.json 文件
没有 lock 文件
- 分析依赖关系,这是因为我们可能包会依赖其他的包,并且多个包之间会产生相同依赖的情况
- 从 registry 仓库中下载压缩包(如果我们设置了镜像,那么会从镜像服务器下载压缩包)
- 获取到压缩包后会对压缩包进行缓存(从 npm5 开始有的)
- 将压缩包解压到项目的 node_modules 文件夹中(前面我们讲过,require 的查找顺序会在该包下面查找)
有 lock 文件
- 检测 lock 中包的版本是否和 package.json 中一致(会按照 semver 版本规范检测)
- 不一致,那么会重新构建依赖关系,直接会走顶层的流程
- 一致的情况下,会去优先查找缓存
- 没有找到,会从 registry 仓库下载,直接走顶层流程
- 查找到,会获取缓存中的压缩文件,并且将压缩文件解压到 node_modules 文件夹中
- 检测 lock 中包的版本是否和 package.json 中一致(会按照 semver 版本规范检测)

package-lock
- name:项目的名称
- version:项目的版本
- lockfileVersion:lock 文件的版本
- requires:使用 requires 来跟踪模块的依赖关系
- dependencies:项目的依赖
- 当前项目依赖 axios,但是 axios 依赖 follow-redireacts
- axios 中的属性如下
- version 表示实际安装的 axios 的版本
- resolved 用来记录下载的地址,registry 仓库中的位置
- requires/dependencies 记录当前模块的依赖
- integrity 用来从缓存中获取索引,再通过索引去获取压缩包文件
其他命令
我们这里再介绍几个比较常用的
卸载某个依赖包
1
2
3npm uninstall package
npm uninstall package --save-dev
npm uninstall package -D强制重新 build
1
npm rebuild
获取缓存位置
1
npm config get cache
清除缓存
1
npm cache clean
npm 的命令其实是非常多的
- https://docs.npmjs.com/cli-documentation/cli
- 更多的命令,可以根据需要查阅官方文档
yarn
- 另一个 node 包管理工具 yarn
- yarn 是由Facebook、Google、Exponent 和 Tilde 联合推出了一个新的 JS 包管理工具,它有如下的优点
- 速度快,支持并行安装。无论 npm 还是 yarn 在执行包的安装时,都会执行一系列任务。npm 是按照队列执行每个 package,也就是说必须要等到当前 package 安装完成之后,才能继续后面的安装。而 yarn 是同步执行所有任务,提高了性能。
- 离线模式,如果之前已经安装过一个软件包,用 yarn 再次安装时之间从缓存中获取,就不用像 npm 那样再从网络下载了
- yarn 是为了弥补 早期 npm 的⼀些缺陷而出现的,因为早期的 npm 存在很多的缺陷,比如安装依赖速度很慢、版本依赖混乱等等一系列的问题。虽然从 npm5 版本开始,进行了很多的升级和改进,但是依然很多人喜欢使用 yarn
- yarn 是由Facebook、Google、Exponent 和 Tilde 联合推出了一个新的 JS 包管理工具,它有如下的优点
cnpm
由于一些特殊的原因,某些情况下我们没办法很好的从 https://registry.npmjs.org 下载下来一些需要的包
查看 npm 镜像
- npm config get registry
我们可以直接设置 npm 的镜像
- npm config set registry https://registry.npm.taobao.org
但是对于大多数人来说(比如我),并不希望将 npm 镜像修改了
- 第一,不太希望随意修改 npm 原本从官方下来包的渠道
- 第二,担心某天淘宝的镜像挂了或者不维护了,又要改来改去
这个时候,我们可以使用 cnpm,并且将 cnpm 设置为淘宝的镜像
1
2npm install -g cnpm --registry=https://registry.npm.taobao.org
cnpm config get registry
npx
npx 是 npm5.2 之后自带的一个命令
- npx 的作用非常多,但是比较常见的是使用它来调用项目中的某个模块的指令
我们以 yarn 为例
- 全局安装的是 yarn 1.22.19
- 项目安装的是 yarn 0.24.24
如果我在终端执行 yarn --version 使用的是哪一个命令呢
- 显示结果会是 yarn 1.22.19,事实上使用的是全局的,为什么呢
- 原因非常简单,在当前目录下找不到 yarn 时,就会去全局找,并且执行命令
如何解决这个问题呢?
局部命令的执行
那么如何使用局部的 yarn,常见的是两种方式
- 方式一:明确查找到 node_module 下面的 yarn
1
2# cd ./node_modules/.bin
yarn --version- 方式二:在 scripts 定义脚本,来执行 yarn
1
2
3"scripts": {
"yarn": "yarn --version"
}- 方式三:使用 npx
- npx yarn --version
npx 的原理非常简单,它会到当前目录的node_modules/.bin目录下查找对应的命令
window 执行某一个命令
优先在当前目录下找命令对应的程序
如果找不到,那么就会去环境变量中查找
发布自己的包
- 注册 npm 账号:https://www.npmjs.com
- 在命令行登录:npm login
- 修改 package.json
- 发布到 npm registry 上:npm publish
- 更新仓库
- 修改版本号(最好符合 semver 规范)
- 重新发布
- 删除发布的包:npm unpublish
- 让发布的包过期:npm deprecate
pnpm
- 什么是 pnpm 呢?
- pnpm 是⼀个速度快、节省磁盘空间的软件包管理器
- 特点是
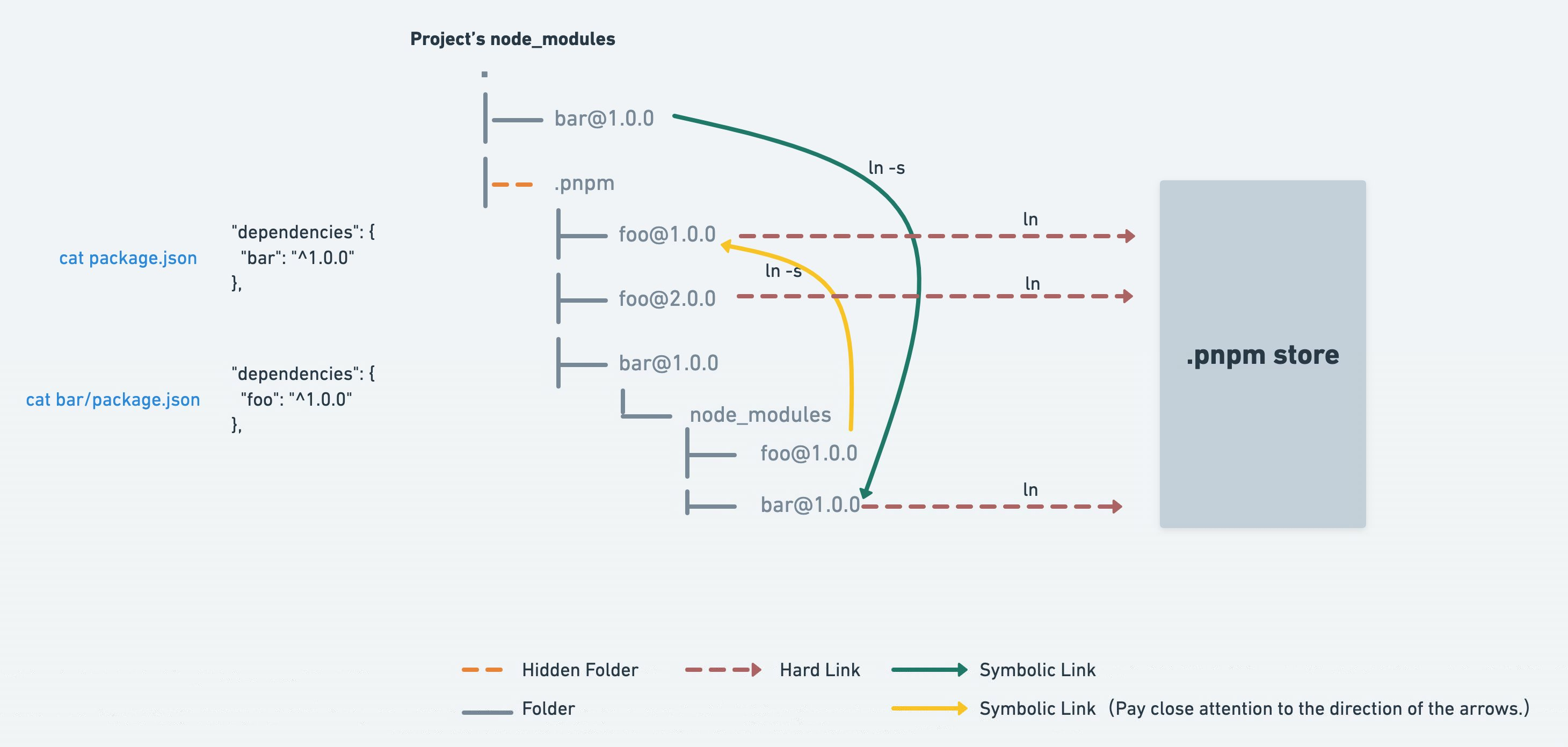
- 快速:pnpm 是同类工具速度的将近 2 倍
- 高效:node_modules 中的所有文件均链接自单一存储位置
- 支持单体仓库:pnpm 内置了对单个源码仓库中包含多个软件包的支持
- 权限严格:pnpm 创建的 node_modules 默认并非扁平结构,因此代码无法对任意软件包进行访问
- 当使用 npm 或 yarn 时,如果你有 100 个项目,并且所有项目都有一个相同的依赖包,那么,你在硬盘上就需要保存 100 份该相同依赖包的副本。为了解决上面的问题,就出现了 pnpm,使用 pnpm 安装的依赖包将被存放在一个统一的位置
- 当安装软件包时,其包含的所有文件都会硬链接到此位置,而不会占用额外的硬盘空间
- pinia 是软连接和硬链接相结合,方便在项目之间共享相同版本的依赖包
硬链接和软连接的概念
- 硬链接(hard link)
- 硬链接(英语:hard link)是电脑文件系统中的多个文件平等地共享同一个文件存储单元
- 删除一个文件名字后,还可以用其它名字继续访问该文件
- 符号链接(软链接 soft link、Symbolic link)
- 符号链接(软链接、Symbolic link)是一类特殊的文件
- 其包含有一条以绝对路径或者相对路径的形式指向其它文件或者目录的引用
硬链接和软连接的演练
文件的拷贝:copy foo.js foo_copy.js
文件的硬链接:mklink /H foo_hard.js foo.js
文件的软连接: mklink foo_soft.js foo.js



pnpm 到底做了什么呢
当使用 npm 或 Yarn 时,如果你有 100 个项目,并且所有项目都有一个相同的依赖包,那么, 你在硬盘上就需要保存 100 份该相同依赖包的副本
如果是使用 pnpm,依赖包将被 存放在一个统一的位置,因此
- 如果你对同一依赖包使用相同的版本,那么磁盘上只有这个依赖包的一份文件
- 如果你对同一依赖包需要使用不同的版本,则仅有 版本之间不同的文件会被存储起来
- 所有文件都保存在硬盘上的统一的位置
- 当安装软件包时, 其包含的所有文件都会硬链接到此位置,而不会占用 额外的硬盘空间
- 这让你可以在项目之间方便地共享相同版本的 依赖包
创建非扁平的目录
当使用 npm 或 yarn 安装依赖包时,所有依赖包都将被提升到 node_modules 的根目录下
其结果是,代码可以访问 本不属于当前项目所安装的依赖包
安装和使用
那么我们应该如何安装 pnpm 呢?
- 官网提供了很多种方式来安装 pnpm:https://www.pnpm.cn/installation
- 因为我们每个同学都要求安装过 Node,Node 中有 npm,所以我们通过 npm 安装即可
1
npm i pnpm -g
以下 是一个与 npm 等价命令的对照表,帮助你快速入门
npm 命令 pnpm 等价命令 npm install pnpm install npm install pnpm add npm uninstall pnpm remove npm run pnpm 更多命令和用法可以参考 pnpm 的官网:https://pnpm.io/zh
存储位置
在 pnpm7.0 之前,统一的存储位置是
C:\Users\xxx\.pnpm-score中的在 pnpm7.0 之后,统一的存储位置进行了更改:
<pnpm home directory>/store- 在 Linux 上,默认是 ~/.local/share/pnpm/store
- 在 Windows 上:
C:\Users\xxx\AppData\Local\pnpm\score - 在 macOS 上: ~/Library/pnpm/store
我们可以通过一些终端命令获取这个目录:获取当前活跃的 store 目录
- pnpm store path
另外一个非常重要的 store 命令是 prune:从 store 中删除当前未被引用的包来释放 store 的空间
- pnpm store prune
文件模块
- fs 是 File System 的缩写,表示文件系统
- 对于任何一个为服务器端服务的语言或者框架通常都会有自己的文件系统
- 因为服务器需要将各种数据、文件等放置到不同的地方
- 比如用户数据可能大多数是放到数据库中的
- 比如某些配置文件或者用户资源(图片、音视频)都是以文件的形式存在于操作系统上的
- Node 也有自己的文件系统操作模块,就是 fs
- 借助于 Node 帮我们封装的文件系统,我们可以在任何的操作系统(window、Mac OS、Linux)上面直接去操作文件
- 这也是Node 可以开发服务器的一大原因,也是它可以成为前端自动化脚本等热门工具的原因
API
- Node 文件系统的 API 非常的多
- https://nodejs.org/docs/latest-v16.x/api/fs.html
- 我们不可能,也没必要一个个去学习
- 这个更多的应该是作为一个 API 查询的手册,等用到的时候查询即可
- 学习阶段我们只需要学习最常用的即可
- 但是这些 API 大多数都提供三种操作方式
- 方式一:同步操作文件:代码会被阻塞,不会继续执行
- 方式二:异步回调函数操作文件:代码不会被阻塞,需要传入回调函数,当获取到结果时,回调函数被执行
- 方式三:异步 Promise 操作文件:代码不会被阻塞,通过 fs.promises 调用方法操作,会返回一个 Promise,可以通过 then、catch 进行处理
获取一个文件的状态
我们这里以获取一个文件的状态为例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18const fs = require("fs");
// 1.同步读取
const res1 = fs.readFileSync("./aaa.txt", { encoding: "utf8" });
console.log(res1);
console.log("后续的代码 1");
// 2.异步读取: 回调函数
fs.readFile("./aaa.txt", { encoding: "utf8" }, (err, data) => {
console.log("读取文件结果:", data);
});
console.log("后续的代码 2");
// 3.异步读取: Promise
fs.promises
.readFile("./aaa.txt", { encoding: "utf-8" })
.then((res) => console.log("获取到结果:", res))
.catch((err) => console.log("发生了错误:", err));
文件描述符
文件描述符(File descriptors)是什么呢?
- 在常见的操作系统上,对于每个进程,内核都维护着一张当前打开着的文件和资源的表格
- 每个打开的文件都分配了一个称为文件描述符的简单的数字标识符
- 在系统层,所有文件系统操作都使用这些文件描述符来标识和跟踪每个特定的文件
- Windows 系统使用了一个虽然不同但概念上类似的机制来跟踪资源
为了简化用户的工作,Node.js 抽象出操作系统之间的特定差异,并为所有打开的文件分配一个数字型的文件描述符
fs.open() 方法用于分配新的文件描述符
- 一旦被分配,则文件描述符可用于从文件读取数据、向文件写入数据、或请求关于文件的信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18const fs = require("fs");
// 打开一个文件
fs.open("./bbb.txt", (err, fd) => {
if (err) {
console.log("打开文件错误:", err);
return;
}
// 1.获取文件描述符
console.log(fd);
// 2.读取到文件的信息
fs.fstat(fd, (err, stats) => {
if (err) return;
console.log(stats);
// 3.手动关闭文件
fs.close(fd);
});
});
文件的读写
如果我们希望对文件的内容进行操作,这个时候可以使用文件的读写
- fs.readFile(path[, options], callback):读取文件的内容
- fs.writeFile(file, data[, options], callback):在文件中写入内容
1
2
3
4
5
6
7
8
9
10
11
12
13const fs = require("fs");
// 1.有一段内容(客户端传递过来)
const content = "hello world, my name is strive";
// 2.文件的写入操作
fs.writeFile("./ccc.txt", content, { encoding: "utf8", flag: "a" }, (err) => {
if (err) {
console.log("文件写入错误:", err);
} else {
console.log("文件写入成功");
}
});在上面的代码中,你会发现有一个对象类型,这个是写入时填写的 option 参数
- flag:写入的方式
- w 打开文件写入,默认值
- w+ 打开文件进行读写(可读可写),如果不存在则创建文件
- r 打开文件读取,读取时的默认值
- r+ 打开文件进行读写,如果不存在那么抛出异常
- a 打开要写入的文件,将流放在文件末尾。如果不存在则创建文件
- a+ 打开文件以进行读写(可读可写),将流放在文件末尾。如果不存在则创建文件
- flag 的值有很多:https://nodejs.org/dist/latest-v14.x/docs/api/fs.html#fs_file_system_flags
- encoding:字符的编码
- 目前基本用的都是 UTF-8 编码
- 如果不填写 encoding,返回的结果是 Buffer
- 关于字符编码的文章:https://www.jianshu.com/p/899e749be47c
- flag:写入的方式
文件夹操作
新建一个文件夹
- 使用 fs.mkdir()或 fs.mkdirSync()创建一个新文件夹
1
2
3
4const fs = require("fs");
// 创建文件夹 directory
fs.mkdir("./ddd", (err) => console.log(err));获取文件夹的内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18const fs = require("fs");
// 读取文件夹
// 1.读取文件夹, 获取到文件夹中文件的字符串
fs.readdir("./infos", (err, files) => {
console.log(files);
});
// 2.读取文件夹, 获取到文件夹中文件的信息
fs.readdir("./infos", { withFileTypes: true }, (err, files) => {
files.forEach((item) => {
if (item.isDirectory()) {
console.log("item是一个文件夹:", item.name);
} else {
console.log("item是一个文件:", item.name);
}
});
});文件重命名
1
2
3
4
5
6
7
8
9
10
11const fs = require("fs");
// 1.对文件夹进行重命名
fs.rename("./infos", "./hhhh", (err) => {
console.log("重命名结果:", err);
});
// 2.对文件重命名
fs.rename("./ccc.txt", "./ddd.txt", (err) => {
console.log("重命名结果:", err);
});
事件模块
Node 中的核心 API 都是基于异步事件驱动的
- 在这个体系中,某些对象(发射器(Emitters))发出某一个事件
- 我们可以监听这个事件(监听器 Listeners),并且传入的回调函数,这个回调函数会在监听到事件时调用
发出事件和监听事件都是通过 EventEmitter 类来完成的,它们都属于 events 对象
- emitter.on(eventName, listener):监听事件,也可以使用 addListener
- emitter.off(eventName, listener):移除事件监听,也可以使用 removeListener
- emitter.emit(eventName[, …args]):发出事件,可以携带一些参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// events 模块中的事件总线
const EventEmitter = require("events");
// 创建 EventEmitter 的实例
const emitter = new EventEmitter();
// 监听事件
function handleChange(name, age) {
console.log("监听change的事件:", name, age);
}
emitter.on("change", handleChange);
// 发射事件
setTimeout(() => {
emitter.emit("change", "strive", 18);
emitter.off("change", handleChange);
}, 1000);
setTimeout(() => {
emitter.emit("change");
console.log("-------");
}, 2000);
常见的方法
EventEmitter 的实例有一些属性,可以记录一些信息
- emitter.eventNames():返回当前 EventEmitter 对象注册的事件字符串数组
- emitter.getMaxListeners():返回当前 EventEmitter 对象的最大监听器数量,可以通过 setMaxListeners()来修改,默认是 10
- emitter.listenerCount(事件名称):返回当前 EventEmitter 对象某一个事件名称,监听器的个数
- emitter.listeners(事件名称):返回当前 EventEmitter 对象某个事件监听器上所有的监听器数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19const EventEmitter = require("events");
const ee = new EventEmitter();
ee.on("aaa", () => {});
ee.on("aaa", () => {});
ee.on("aaa", () => {});
ee.on("bbb", () => {});
ee.on("bbb", () => {});
// 1.获取所有监听事件的名称
console.log(ee.eventNames());
// 2.获取监听最大的监听个数
console.log(ee.getMaxListeners());
// 3.获取某一个事件名称对应的监听器个数
console.log(ee.listenerCount("aaa"));
// 4.获取某一个事件名称对应的监听器函数(数组)
console.log(ee.listeners("aaa"));EventEmitter 的实例方法补充
- emitter.once(eventName, listener):事件监听一次
- emitter.prependListener():将监听事件添加到最前面
- emitter.prependOnceListener():将监听事件添加到最前面,但是只监听一次
- emitter.removeAllListeners([eventName]):移除所有的监听器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20const EventEmitter = require("events");
const ee = new EventEmitter();
// 1.once: 事件监听只监听一次(第一次发射事件的时候进行监听)
ee.once("change", () => {
console.log("on监听change1");
});
// 2.prependListener: 将事件监听添加到最前面
ee.prependListener("change", () => {
console.log("on监听change2");
});
ee.emit("change");
// 3.移除所有的事件监听
// 不传递参数的情况下, 移除所有事件名称的所有事件监听
// 在传递参数的情况下, 只会移除传递的事件名称的事件监听
ee.removeAllListeners("change");
Buffer
数据的二进制
- 计算机中所有的内容:文字、数字、图片、音频、视频最终都会使用二进制来表示
- JavaScript 可以直接去处理非常直观的数据:比如字符串,我们通常展示给用户的也是这些内容
- 不对啊,JavaScript 不是也可以处理图片吗?
- 事实上在网页端,图片我们一直是交给浏览器来处理的
- JavaScript 或者 HTML,只是负责告诉浏览器一个图片的地址
- 浏览器负责获取这个图片,并且最终将这个图片渲染出来
- 但是对于服务器来说是不一样的
- 服务器要处理的本地文件类型相对较多
- 比如某一个保存文本的文件并不是使用 utf-8 进行编码的,而是用 GBK,那么我们必须读取到他们的二进制数据,再通过 GKB 转换成对应的文字
- 比如我们需要读取的是一张图片数据(二进制),再通过某些手段对图片数据进行二次的处理(裁剪、格式转换、旋转、添加滤镜),Node 中有一个 Sharp 的库,就是读取图片或者传入图片的 Buffer 对其再进行处理
- 比如在 Node 中通过 TCP 建立长连接,TCP 传输的是字节流,我们需要将数据转成字节再进行传入,并且需要知道传输字节的大小(客户端需要根据大小来判断读取多少内容)
Buffer 和二进制
- 我们会发现,对于前端开发来说,通常很少会和二进制直接打交道,但是对于服务器端为了做很多的功能,我们必须直接去操作其二进制的数据
- 所以 Node 为了可以方便开发者完成更多功能,提供给了我们一个类 Buffer,并且它是全局的
- 我们前面说过,Buffer 中存储的是二进制数据,那么到底是如何存储呢?
- 我们可以将 Buffer 看成是一个存储二进制的数组
- 这个数组中的每一项,可以保存 8 位二进制: 0000 0000
- 为什么是 8 位呢?
- 在计算机中,很少的情况我们会直接操作一位二进制,因为一位二进制存储的数据是非常有限的
- 所以通常会将 8 位合在一起作为一个单元,这个单元称之为一个字节(byte)
- 也就是说 1byte = 8bit,1kb=1024byte,1M=1024kb
- 比如很多编程语言中的int 类型是 4 个字节,long 类型时 8 个字节
- 比如TCP 传输的是字节流,在写入和读取时都需要说明字节的个数
- 比如RGB 的值分别都是 255,所以本质上在计算机中都是用一个字节存储的
Buffer 和字符串
Buffer 相当于是一个字节的数组,数组中的每一项对应一个字节的大小
1
2const buffer1 = new Buffer("hello"); // 不推荐
console.log(buffer1);如果我们希望将一个字符串放入到 Buffer 中,是怎么样的过程呢?
1
// 字符串--ascii编码--> 16进制--存储--> Buffer
它是怎么样的过程呢?
1
2const buffer2 = Buffer.from("hello");
console.log(buffer2);如果是中文呢?
- 默认编码:utf-8
1
2
3const buffer3 = Buffer.from("你好啊, hhh");
console.log(buffer3);
console.log(buffer3.toString());如果编码和解码不同
1
2
3
4const buffer4 = Buffer.from("哈哈哈", "utf16le");
console.log(buffer4);
// 解码操作
console.log(buffer4.toString("utf16le"));
Buffer.alloc
我们会发现创建了一个 8 位长度的 Buffer,里面所有的数据默认为 00
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 1.创建一个bufferfer对象
// 8个字节大小的bufferfer内存空间
const bufferfer = bufferfer.alloc(8);
console.log(buffer);
// 2.手动对每个字节进行访问
console.log(buffer[0]);
console.log(buffer[1]);
// 3.手动对每个字节进行操作
buffer[0] = 100;
buffer[1] = 0x66;
console.log(buffer);
console.log(buffer.toString());
buffer[2] = "m".charCodeAt();
console.log(buffer);
Buffer 和文件读取
文本文件的读取
1
2
3
4const fs = require("fs");
fs.readFile("./aaa.txt", { encoding: "utf-8" }, (err, data) => {
console.log(data);
});图片文件的读取
1
2
3
4const fs = require("fs");
fs.readFile("./logo.png", (err, data) => {
console.log(data);
});
Stream
- 什么是 Stream(小溪、小河,在编程中通常翻译为流)呢?
- 我们的第一反应应该是流水,源源不断的流动
- 程序中的流也是类似的含义,我们可以想象当我们从一个文件中读取数据时,文件的二进制(字节)数据会源源不断的被读取到我们程序中
- 而这个一连串的字节,就是我们程序中的流
- 所以,我们可以这样理解流
- 流是连续字节的一种表现形式和抽象概念
- 流应该是可读的,也是可写的
- 在之前学习文件的读写时,我们可以直接通过 readFile 或者 writeFile 方式读写文件,为什么还需要流呢?
- 直接读写文件的方式,虽然简单,但是无法控制一些细节的操作
- 比如从什么位置开始读、读到什么位置、一次性读取多少个字节
- 读到某个位置后,暂停读取,某个时刻恢复继续读取等等
- 或者这个文件非常大,比如一个视频文件,一次性全部读取并不合适
文件读写的流
- 事实上 Node 中很多对象是基于流实现的
- http 模块的Request和Response对象
- 官方文档:另外所有的流都是 EventEmitter 的实例
- 那么在 Node 中都有哪些流呢?
- Node.js 中有四种基本流类型
- Writable:可以向其写入数据的流(例如 fs.createWriteStream())
- Readable:可以从中读取数据的流(例如 fs.createReadStream())
- Duplex:同时为 Readable 和 Writable(例如 net.Socket)
- Transform:Duplex 可以在写入和读取数据时修改或转换数据的流(例如 zlib.createDeflate())
- 这里我们通过 fs 的操作,讲解一下 Writable、Readable,另外两个大家可以自行学习一下
Readable
之前我们读取一个文件的信息
1
2
3
4
5
6
7
8const fs = require("fs");
// 一次性读取
// 缺点一: 没有办法精准控制从哪里读取, 读取什么位置
// 缺点二: 读取到某一个位置的, 暂停读取, 恢复读取
// 缺点三: 文件非常大的时候, 多次读取
fs.readFile("./aaa.txt", (err, data) => {
console.log(data);
});这种方式是一次性将一个文件中所有的内容都读取到程序(内存)中,但是这种读取方式就会出现我们之前提到的很多问题
- 文件过大、读取的位置、结束的位置、一次读取的大小
这个时候,我们可以使用 createReadStream,我们来看几个参数,更多参数可以参考官网
- start:文件读取开始的位置
- end:文件读取结束的位置
- highWaterMark:一次性读取字节的长度,默认是 64kb
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33const fs = require("fs");
// 通过流读取文件, 创建一个可读流
// start: 从什么位置开始读取
// end: 读取到什么位置后结束(包括end位置字节)
const readStream = fs.createReadStream("./aaa.txt", {
start: 6,
end: 10,
highWaterMark: 3,
});
// 监听读取到的数据
readStream.on("data", (data) => {
console.log(data.toString());
readStream.pause();
setTimeout(() => {
readStream.resume();
}, 2000);
});
// 补充其他的事件监听
readStream.on("open", (fd) => {
console.log("通过流将文件打开", fd);
});
readStream.on("end", () => {
console.log("已经读取到end位置");
});
readStream.on("close", () => {
console.log("文件读取结束, 并且被关闭");
});
Writable
之前我们写入一个文件的方式是这样的
1
2
3
4
5const fs = require("fs");
// 一次性写入内容
fs.writeFile("./bbb.txt", "你好啊", (err) => {
console.log("写入文件结果:", err);
});这种方式相当于一次性将所有的内容写入到文件中,但是这种方式也有很多问题
- 比如我们希望一点点写入内容,精确每次写入的位置等
这个时候,我们可以使用 createWriteStream,我们来看几个参数,更多参数可以参考官网
- flags:默认是 w,如果我们希望是追加写入,可以使用 a 或者 a+
- start:写入的位置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35const fs = require("fs");
// 创建一个写入流
const writeStream = fs.createWriteStream("./ccc.txt", {
// mac 上面是没有问题
// flags: 'a+',
flags: "r+",
start: 5, // window 上面是需要使用 r+
});
writeStream.on("open", (fd) => {
console.log("文件被打开", fd);
});
writeStream.write("******");
writeStream.write("------");
writeStream.write("bbbb", (err) => {
console.log("写入完成:", err);
});
writeStream.on("finish", () => {
console.log("写入完成了");
});
writeStream.on("close", () => {
console.log("文件被关闭");
});
// 3.写入完成时, 需要手动去掉用close方法
// writeStream.close()
// 4.end方法
// 操作一: 将最后的内容写入到文件中, 并且关闭文件
// 操作二: 关闭文件
writeStream.end("哈哈哈哈");
pipe
正常情况下,我们可以将读取到的 输入流,手动的放到 输出流中进行写入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22const fs = require("fs");
// 1.方式一: 一次性读取和写入文件
fs.readFile("./foo.txt", (err, data) => {
console.log(data);
fs.writeFile("./foo_copy_1.txt", data, (err) => {
console.log("写入文件完成", err);
});
});
// 2.方式二: 创建可读流和可写流
const readStream1 = fs.createReadStream("./foo.txt");
const writeStream1 = fs.createWriteStream("./foo_copy_2.txt");
readStream1.on("data", (data) => writeStream1.write(data));
readStream1.on("end", () => [writeStream1.close()]);
// 3.在可读流和可写流之间建立一个管道
const readStream2 = fs.createReadStream("./foo.txt");
const writeStream2 = fs.createWriteStream("./foo_copy_3.txt");
readStream2.pipe(writeStream2);
Web 服务器
- 什么是 Web 服务器?
- 当应用程序(客户端)需要某一个资源时,可以向一台服务器,通过 http 请求获取到这个资源
- 提供资源的这个服务器,就是一个 Web 服务器
- 目前有很多开源的 Web 服务器:Nginx、Apache(静态)、Apache Tomcat(静态、动态)、Node.js
http 模块
在 Node 中,提供 web 服务器的资源返回给浏览器,主要是通过 http 模块
我们先简单对它做一个使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16const http = require("http");
// 创建一个http对应的服务器
const server = http.createServer((request, response) => {
// request 对象中包含本次客户端请求的所有信息
// response 对象用于给客户端返回结果的
response.end("Hello World");
});
// 开启对应的服务器, 并且告知需要监听的端口
// 监听端口时, 监听 1024以上的端口, 65535以下的端口
// 1025 ~ 65535之间的端口
// 2个字节 => 256*256 => 65536 => 0 ~ 65535
server.listen(8000, () => {
console.log("服务器已经开启成功了");
});
创建服务器
创建服务器对象,我们是通过 createServer 来完成的
- http.createServer 会返回服务器的对象
- 底层其实使用直接 new Server 对象
1
2
3function createServer(opts, requestListener) {
return new Server(opts, requestListener);
}那么,当然,我们也可以自己来创建这个对象
上面我们已经看到,创建 Server 时会传入一个回调函数,这个回调函数在被调用时会传入两个参数
1
2
3
4
5
6
7const server = new http.Server((req, res) => {
res.end("Hello World");
});
server.listen(3000, () => {
console.log("服务器已经开启成功了");
});- req:request 请求对象,包含请求相关的信息
- res:response 响应对象,包含我们要发送给客户端的信息
监听主机和端口号
- Server 通过listen 方法来开启服务器,并且在某一个主机和端口上监听网络请求
- 也就是当我们通过 ip:port 的方式发送到我们监听的 Web 服务器上时
- 我们就可以对其进行相关的处理
- listen 函数有三个参数
- 端口 port:可以不传, 系统会默认分配端, 后续项目中我们会写入到环境变量中
- 主机 host:通常可以传入 localhost、ip 地址 127.0.0.1、或者 ip 地址 0.0.0.0,默认是 0.0.0.0
- localhost:本质上是一个域名,通常情况下会被解析成 127.0.0.1
- 127.0.0.1:回环地址(Loop Back Address),表达的意思其实是我们主机自己发出去的包,直接被自己接收
- 正常的数据库包经常 应用层 - 传输层 - 网络层 - 数据链路层 - 物理层
- 而回环地址,是在网络层直接就被获取到了,是不会经常数据链路层和物理层的
- 比如我们监听 127.0.0.1 时,在同一个网段下的主机中,通过 ip 地址是不能访问的
- 0.0.0.0
- 监听 IPV4 上所有的地址,再根据端口找到不同的应用程序
- 比如我们监听 0.0.0.0 时,在同一个网段下的主机中,通过 ip 地址是可以访问的
- 回调函数:服务器启动成功时的回调函数
request
在向服务器发送请求时,我们会携带很多信息,比如
- 本次请求的 URL,服务器需要根据不同的 URL 进行不同的处理
- 本次请求的请求方式,比如GET、POST 请求传入的参数和处理的方式是不同的
- 本次请求的 headers 中也会携带一些信息,比如客户端信息、接受数据的格式、支持的编码格式等
- 等等…
这些信息,Node 会帮助我们封装到一个request 的对象中,我们可以直接来处理这个 request 对象
1
2
3
4
5
6
7
8
9
10
11
12
13const http = require("http");
const server = http.createServer((req, res) => {
console.log(req.url);
console.log(req.method);
console.log(req.headers);
res.end("hello world");
});
server.listen(8000, () => {
console.log("服务器开启成功");
});
返回响应结果
如果我们希望给客户端响应的结果数据,可以通过两种方式
- Write 方法:这种方式是直接写出数据,但是并没有关闭流
- end 方法:这种方式是写出最后的数据,并且写出后会关闭流
1
2
3
4
5
6
7
8
9
10
11
12
13const http = require("http");
const server = http.createServer((req, res) => {
// request 对象本质是上一个 readable 可读流
res.write("Hello World");
res.write("哈哈哈哈");
res.end("本次写出已经结束");
});
server.listen(8000, () => {
console.log("服务器开启成功");
});如果我们没有调用 end,客户端将会一直等待结果
- 所以客户端在发送网络请求时,都会设置超时时间
返回状态码
Http 状态码(Http Status Code)是用来表示 Http 响应状态的数字代码
- Http 状态码非常多,可以根据不同的情况,给客户端返回不同的状态码
- MDN 响应码解析地址:https://developer.mozilla.org/zh-CN/docs/web/http/status
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16const http = require("http");
const server = http.createServer((req, res) => {
// 响应状态码
// 1.方式一: statusCode
// res.statusCode = 403
// 2.方式二: setHead 响应头
res.writeHead(401);
res.end("hello world");
});
server.listen(8000, () => {
console.log("服务器开启成功");
});
响应头文件
返回头部信息,主要有两种方式
- res.setHeader:一次写入一个头部信息
- res.writeHead:同时写入 header 和 status
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17const http = require("http");
const server = http.createServer((req, res) => {
// 设置header信息: 数据的类型以及数据的编码格式
// 1.单独设置某一个header
// res.setHeader('Content-Type', 'text/plain;charset=utf8;')
// 2.和http status code一起设置
res.writeHead(200, { "Content-Type": "application/json;charset=utf8;" });
const list = [{ name: "strive", age: 18 }];
res.end(JSON.stringify(list));
});
server.listen(8000, () => {
console.log("服务器开启成功");
});Header 设置 Content-Type 有什么作用呢?
- 默认客户端接收到的是字符串,客户端会按照自己默认的方式进行处理
文件上传 – 错误示范
如果是一个很大的文件需要上传到服务器端,服务器端进行保存应该如何操作呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22const http = require("http");
const fs = require("fs");
const server = http.createServer((req, res) => {
const writeStream = fs.createWriteStream("./foo.png", { flags: "a+" });
const fileSize = req.headers["content-length"];
let currentSize = 0;
// 客户端传递的数据是表单数据(请求体)
req.on("data", (data) => {
currentSize += data.length;
console.log(data);
writeStream.write(data); // 没有对传递过来的数据进行处理
console.log(`文件上传进度: ${(currentSize / fileSize) * 100}%`);
});
req.on("end", () => res.end("文件上传成功"));
});
server.listen(8000, () => console.log("服务器开启成功"));
文件上传 – 正确做法
对传递过来的数据进行处理,拿到图片对应的数据,再进行存储
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38const http = require("http");
const fs = require("fs");
const server = http.createServer((req, res) => {
req.setEncoding("binary");
const boundary = req.headers["content-type"]
.split("; ")[1]
.replace("boundary=", "");
console.log(boundary);
// 客户端传递的数据是表单数据(请求体)
let formData = "";
req.on("data", (data) => {
formData += data;
});
req.on("end", () => {
console.log(formData);
// 1.截图从 image/jpeg 位置开始后面所有的数据
const imgType = "image/jpeg";
const imageTypePosition = formData.indexOf(imgType) + imgType.length;
let imageData = formData.substring(imageTypePosition);
// 2.imageData 开始位置会有两个空格
imageData = imageData.replace(/^\s\s*/, "");
// 3.替换最后的 boundary
imageData = imageData.substring(0, imageData.indexOf(`--${boundary}--`));
// 4.将 imageData 的数据存储到文件中
fs.writeFile("./bar.png", imageData, "binary", () => {
res.end("文件上传成功");
});
});
});
server.listen(8000, () => console.log("服务器开启成功"));1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24<script src="https://unpkg.com/axios/dist/axios.min.js"></script>
<input type="file" />
<button>上传</button>
<script>
const btnEl = document.querySelector("button");
btnEl.onclick = function () {
// 1.创建表单对象
const formData = new FormData();
// 2.将选中的图片文件放入表单
const inputEl = document.querySelector("input");
formData.set("photo", inputEl.files[0]);
// 3.发送post请求, 将表单数据携带到服务器(axios)
axios({
method: "post",
url: "http://localhost:8000",
data: formData,
headers: { "Content-Type": "multipart/form-data" },
});
};
</script>
express
- 前面我们已经学习了使用 http 内置模块来搭建 Web 服务器,为什么还要使用框架?
- 原生 http 在进行很多处理时,会较为复杂
- 有 URL 判断、Method 判断、参数处理、逻辑代码处理等,都需要我们自己来处理和封装
- 并且所有的内容都放在一起,会非常的混乱
- 目前在 Node 中比较流行的 Web 服务器框架是 express、koa
- express 早于 koa 出现,并且在 Node 社区中迅速流行起来
- 我们可以基于 express 快速、方便的开发自己的 Web 服务器
- 并且可以通过一些实用工具和中间件来扩展自己功能
- Express 整个框架的核心就是中间件,理解了中间件其他一切都非常简单!
安装方式
express 的使用过程有两种方式
方式一:通过 express 提供的脚手架,直接创建一个应用的骨架
方式二:从零搭建自己的 express 应用结构
方式一:安装 express-generator
1
2
3
4
5
6
7
8# 安装脚手架
npm install -g express-generator
# 创建项目
express express-demo
# 安装依赖
npm install
# 启动项目
node bin/www方式二:从零搭建自己的 express 应用结构
1
npm init -y
基本使用
我们来创建第一个 express 项目
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15const express = require("express");
const app = express();
app.post("/login", (req, res) => {
res.end("登录");
});
app.get("/home", (req, res) => {
res.end("首页");
});
app.listen(9000, () => {
console.log("express服务器启动成功");
});- 我们会发现,之后的开发过程中,可以方便的将请求进行分离
- 无论是不同的 URL,还是 get、post 等请求方式
- 这样的方式非常方便我们已经进行维护、扩展
- 当然,这只是初体验,接下来我们来探索更多的用法
请求的路径中如果有一些参数,可以这样表达
- /users/:userId
- 在 request 对象中药获取可以通过 req.params.userId
返回数据,我们可以方便的使用 json
- res.json(数据)方式
- 可以支持其他的方式,可以自行查看文档
- https://www.expressjs.com.cn/guide/routing.html
认识中间件
Express 是一个路由和中间件的 Web 框架,它本身的功能非常少
- Express 应用程序本质上是一系列中间件函数的调用
中间件是什么呢?
- 中间件的本质是传递给 express 的一个回调函数
- 这个回调函数接受三个参数
- 请求对象(request 对象)
- 响应对象(response 对象)
- next 函数(在 express 中定义的用于执行下一个中间件的函数)
中间件中可以执行哪些任务呢?
- 执行任何代码
- 更改请求(request)和响应(response)对象
- 结束请求-响应周期(返回数据)
- 调用栈中的下一个中间件
如果当前中间件功能没有结束请求-响应周期,则必须调用 next()将控制权传递给下一个中间件功能,否则,请求将被挂起
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25const express = require("express");
const app = express();
// 给 express 创建的 app 传入一个回调函数, 传入的这个回调函数就称之为是中间件(middleware)
// app.post("/login", 回调函数 === 中间件)
app.post("/login", (req, res, next) => {
// 1.中间件中可以执行任意代码
console.log("first middleware exec");
// 2.在中间件中修改 req/res 对象
req.name = "哈哈哈";
// 3.可以在中间件中结束响应周期
// res.json({ message: "登录成功, 欢迎回来", code: 0 })
// 4.执行下一个中间件
next();
});
app.use((req, res, next) => console.log("second middleware exec"));
app.listen(9000, () => {
console.log("express服务器启动成功");
});
应用中间件
那么,如何将一个中间件应用到我们的应用程序中呢?
- express 主要提供了两种方式
- app.use|router.use
- app.use|router.methods
- 可以是 app,也可以是 router
- methods 指的是常用的请求方式,app.get 或 app.post 等
- express 主要提供了两种方式
我们先来学习 use 的用法,因为 methods 的方式本质是 use 的特殊情况
- 案例一:最普通的中间件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25const express = require("express");
const app = express();
// 通过 use 方法注册的中间件是最普通的/简单的中间件
// 通过 use 注册的中间件, 无论是什么请求方式都可以匹配上
// get: /login
// post: /login
// patch: /aaa
app.use((req, res, next) => {
console.log("normal middleware 1");
next();
});
app.use((req, res, next) => {
console.log("normal middleware 2");
});
// 总结: 当 express 接收到客户端发送的网络请求时, 在所有中间中开始进行匹配
// 当匹配到第一个符合要求的中间件时, 那么就会执行这个中间件
// 后续的中间件是否会执行呢? 取决于上一个中间件有没有执行 next
app.listen(9000, () => {
console.log("express服务器启动成功");
});- 案例二:path 匹配中间件
1
2
3
4
5
6
7
8
9
10
11
12
13
14const express = require("express");
const app = express();
// 注册路径匹配的中间件
// 路径匹配的中间件是不会对请求方式(method)进行限制
app.use("/home", (req, res, next) => {
console.log("match /home middleware");
res.end("home data");
});
app.listen(9000, () => {
console.log("express服务器启动成功");
});- 案例三:path 和 method 匹配中间件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18const express = require("express");
const app = express();
// 注册中间件: 对path/method都有限制
app.get("/home", (req, res, next) => {
console.log("match /home get method middleware");
res.end("home data");
});
app.post("/users", (req, res, next) => {
console.log("match /users post method middleware");
res.end("create user success");
});
app.listen(9000, () => {
console.log("express服务器启动成功");
});- 案例四:注册多个中间件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27const express = require("express");
const app = express();
// app.get(路径, 中间件1, 中间件2, 中间件3)
app.get(
"/home",
(req, res, next) => {
console.log("match /home get middleware 1");
next();
},
(req, res, next) => {
console.log("match /home get middleware 2");
next();
},
(req, res, next) => {
console.log("match /home get middleware 3");
next();
},
(req, res, next) => {
console.log("match /home get middleware 4");
}
);
app.listen(9000, () => {
console.log("express服务器启动成功");
});
body
并非所有的中间件都需要我们从零去编写
- express 有内置一些帮助我们完成对 request 解析的中间件
- registry 仓库中也有很多可以辅助我们开发的中间件
在客户端发送 post 请求时,会将数据放到 body 中
- 客户端可以通过 json 的方式传递
- 也可以通过 form 表单的方式传递
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36const express = require("express");
const app = express();
// app.use((req, res, next) => {
// if (req.headers['content-type'] === 'application/json') {
// req.on('data', (data) => {
// const jsonInfo = JSON.parse(data.toString())
// req.body = jsonInfo
// })
// req.on('end', () => {
// next()
// })
// } else {
// next()
// }
// })
// 直接使用 express 提供给我们的中间件
app.use(express.json()); // 解析客户端传递过来的 json
// 解析传递过来 urlencoded 的时候, 默认使用的 node 内置 querystring 模块
// { extended: true }: 不再使用内置的 querystring, 而是使用qs第三方库
app.use(express.urlencoded({ extended: true })); // 解析客户端传递过来的 urlencoded
app.post("/login", (req, res, next) => {
console.log(req.body);
});
app.post("/register", (req, res, next) => {
console.log(req.body);
});
app.listen(9000, () => {
console.log("express服务器启动成功");
});
上传文件中间件
上传文件,我们可以使用 express 官网开发的第三方库:multer
- npm install multer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33const express = require("express");
const multer = require("multer");
const app = express();
// 应用一个 express 编写第三方的中间件
const upload = multer({
// dest: "./uploads",
storage: multer.diskStorage({
destination(req, file, callback) {
callback(null, "./uploads");
},
filename(req, file, callback) {
callback(null, Date.now() + "_" + file.originalname);
},
}),
});
// 上传单文件: singer方法
app.post("/avatar", upload.single("avatar"), (req, res, next) => {
console.log(req.file);
res.end("文件上传成功");
});
// 上传多文件: array方法
app.post("/photos", upload.array("photos"), (req, res, next) => {
console.log(req.files);
res.end("上传多张照片成功");
});
app.listen(9000, () => {
console.log("express服务器启动成功");
});
multer 解析 form-data
如果我们希望借助于 multer 帮助我们解析一些 form-data 中的普通数据,那么我们可以使用 any
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20const express = require("express");
const multer = require("multer");
const app = express();
// express内置的插件
app.use(express.json());
app.use(express.urlencoded({ extended: true }));
// 编写中间件
const formdata = multer();
app.post("/login", formdata.any(), (req, res, next) => {
console.log(req.body);
res.end("登录成功, 欢迎回来");
});
app.listen(9000, () => {
console.log("express服务器启动成功");
});
客户端发送请求的方式
客户端传递到服务器参数的方法常见的是 5 种
- 方式一:通过 get 请求中的 URL 的 query
- 方式二:通过 get 请求中的 URL 的 params
- 方式三:通过 post 请求中的 body 的 json 格式(中间件中已经使用过)
- 方式四:通过 post 请求中的 body 的 x-www-form-urlencoded 格式(中间件使用过)
- 方式五:通过 post 请求中的 form-data 格式(中间件中使用过)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19const express = require("express");
const app = express();
// 1.解析 queryString /info?name='strive'&age=18
app.get("/info", (req, res, next) => {
console.log(req.query);
res.end("data list");
});
// 2.解析 params /users/123456
app.get("/users/:id", (req, res, next) => {
res.end(`获取到${req.params.id}的数据`);
});
app.listen(9000, () => {
console.log("express服务器启动成功");
});
响应数据
- end()
- 类似于 http 中的 response.end 方法,用法是一致的
- json()
- json 方法中可以传入很多的类型:object、array、string、boolean、number、null 等,它们会被转换成 json 格式返回
- status()
- 用于设置状态码
- 注意:这里是一个函数,而不是属性赋值
- 更多响应的方式:https://www.expressjs.com.cn/4x/api.html#res
路由
如果我们将所有的代码逻辑都写在 app 中,那么 app 会变得越来越复杂
- 一方面完整的 Web 服务器包含非常多的处理逻辑
- 另一方面有些处理逻辑其实是一个整体,我们应该将它们放在一起:比如对 users 相关的处理
- 获取用户列表
- 获取某一个用户信息
- 创建一个新的用户
- 删除一个用户
- 更新一个用户
我们可以使用 express.Router 来创建一个路由处理程序
- 一个 Router 实例拥有完整的中间件和路由系统
- 因此,它也被称为 迷你应用程序(mini-app)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30const express = require("express");
const app = express();
// 用户的接口
// 1.将用户的接口直接定义在app中
// app.get('/users', (req, res, next) => {})
// app.get('/users/:id', (req, res, next) => {})
// app.post('/users', (req, res, next) => {})
// app.delete('/users/:id', (req, res, next) => {})
// app.patch('/users/:id', (req, res, next) => {})
// 2.将用户的接口定义在单独的路由对象中
const userRouter = express.Router();
userRouter.get("/", (req, res, next) => res.json("用户列表数据"));
userRouter.get("/:id", (req, res, next) =>
res.json("某一个用户的数据:" + req.params.id)
);
userRouter.post("/", (req, res, next) => res.json("创建用户成功"));
userRouter.delete("/:id", (req, res, next) =>
res.json("删除某一个用户的数据:" + req.params.id)
);
userRouter.patch("/:id", (req, res, next) =>
res.json("修改某一个用户的数据:" + req.params.id)
);
// 让路由生效
app.use("/users", userRouter);
app.listen(9000, () => console.log("express服务器启动成功"));
静态资源服务器
部署静态资源我们可以选择很多方式
- Node 也可以作为静态资源服务器,并且 express 给我们提供了方便部署静态资源的方法
1
2
3
4
5
6
7
8
9
10const express = require("express");
const app = express();
app.use(express.static("./uploads"));
app.use(express.static("./build"));
app.listen(9000, () => {
console.log("express服务器启动成功");
});
服务端的错误处理
express 中处理错误的方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37const express = require("express");
const app = express();
app.use(express.json());
app.post("/login", (req, res, next) => {
const { username, password } = req.body;
if (!username || !password) {
next(-1001);
} else if (username !== "strive" || password !== "123456") {
next(-1002);
} else {
res.json({ code: 0, message: "登录成功, 欢迎回来" });
}
});
// 错误处理的中间件
app.use((errCode, req, res, next) => {
const code = errCode;
let message = "未知的错误信息";
switch (code) {
case -1001:
message = "没有输入用户名和密码";
break;
case -1002:
message = "输入用户名或密码错误";
break;
}
res.json({ code, message });
});
app.listen(9000, () => {
console.log("express服务器启动成功");
});
koa
- 前面我们已经学习了 express,另外一个非常流行的 Node Web 服务器框架就是 Koa
- Koa 官方的介绍
- koa:next generation web framework for node.js
- koa:node.js 的下一代 web 框架
- 事实上,koa 是 express 同一个团队开发的一个新的 Web 框架
- 目前团队的核心开发者 TJ 的主要精力也在维护 Koa,express 已经交给团队维护了
- Koa 旨在为 Web 应用程序和 API 提供更小、更丰富和更强大的能力
- 相对于express 具有更强的异步处理能力
- Koa 的核心代码只有 1600+行,是一个更加轻量级的框架
- 我们可以根据需要安装和使用中间件
- 事实上学习了 express 之后,学习 koa 的过程是很简单的
初体验
我们来体验一下 koa 的 Web 服务器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27const Koa = require("koa");
const app = new Koa();
app.use((ctx, next) => {
// 1.请求对象
console.log(ctx.request); // 请求对象: Koa封装的请求对象
console.log(ctx.req); // 请求对象: Node封装的请求对象
// 2.响应对象
console.log(ctx.response); // 响应对象: Koa封装的响应对象
console.log(ctx.res); // 响应对象: Node封装的响应对象
// 3.其他属性
console.log(ctx.query);
console.log(ctx.params);
next();
});
app.use((ctx, next) => {
console.log("second middleware");
});
app.listen(6000, () => {
console.log("koa服务器启动成功");
});koa 也是通过注册中间件来完成请求操作的
koa 注册的中间件提供了两个参数
ctx:上下文(Context)对象
- koa 并没有像 express 一样,将 req 和 res 分开,而是将它们作为 ctx 的属性
- ctx 代表一次请求的上下文对象
- ctx.request:获取请求对象
- ctx.response:获取响应对象
next:本质上是一个 dispatch,类似于之前的 next
中间件
- koa 通过创建的 app 对象,注册中间件只能通过 use 方法
- Koa 并没有提供 methods 的方式来注册中间件
- 也没有提供 path 中间件来匹配路径
- 但是真实开发中我们如何将路径和 method 分离呢?
- 方式一:根据request 自己来判断
- 方式二:使用第三方路由中间件
路由
koa 官方并没有给我们提供路由的库,我们可以选择第三方库:@koa/router
1
npm install @koa/router
在 app 中将 router.routes()注册为中间件
注意:allowedMethods 用于判断某一个 method 是否支持
- 如果我们请求 get,那么是正常的请求,因为我们有实现 get
- 如果我们请求 put、delete、patch,那么就自动报错:Method Not Allowed,状态码:405
- 如果我们请求 link、copy、lock,那么久自动报错:Not Implemented,状态码:501
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31const Koa = require("koa");
const KoaRouter = require("@koa/router");
const app = new Koa();
// 1.创建路由对象
const userRouter = new KoaRouter({ prefix: "/users" });
// 2.在路由中注册中间件: path/method
userRouter.get("/", (ctx, next) => (ctx.body = "users list data"));
userRouter.get(
"/:id",
(ctx, next) => (ctx.body = "获取某一个用户" + ctx.params.id)
);
userRouter.post("/", (ctx, next) => (ctx.body = "创建用户成功"));
userRouter.delete(
"/:id",
(ctx, next) => (ctx.body = "删除某一个用户" + ctx.params.id)
);
userRouter.patch(
"/:id",
(ctx, next) => (ctx.body = "修改某一个用户" + ctx.params.id)
);
// 3.让路由中的中间件生效
app.use(userRouter.routes());
app.use(userRouter.allowedMethods());
app.listen(6000, () => {
console.log("koa服务器启动成功");
});
参数解析
params、query、json、urlencoded、form-data
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56const Koa = require("koa");
const KoaRouter = require("@koa/router");
const multer = require("@koa/multer"); // npm install koa-multer
const bodyParser = require("koa-bodyparser"); // npm install koa-bodyparser
const app = new Koa();
// 使用第三方中间件解析body数据
app.use(bodyParser());
const formParser = multer();
const userRouter = new KoaRouter({ prefix: "/users" });
/*
* 1.get: params方式, 例子: /:id
* 2.get: query方式, 例子: ?name=strive&age=18
* 3.post: json方式, 例子: {"name": "strive", "age": 18}
* 4.post: x-www-form-urlencoded
* 5.post: form-data
*/
// 1.params
userRouter.get("/:id", (ctx, next) => {
ctx.body = "params " + ctx.params.id;
});
// 2.query
userRouter.get("/", (ctx, next) => {
ctx.body = "query " + JSON.stringify(ctx.query);
});
// 3.json(使用最多)
userRouter.post("/json", (ctx, next) => {
// 注意事项: 不能从 ctx.body 中获取数据
console.log(ctx.request.body, ctx.req.body);
// ctx.body 用于向客户端返回数据
ctx.body = "json " + ctx.request.body;
});
// 4.urlencoded
userRouter.post("/urlencoded", (ctx, next) => {
ctx.body = "urlencoded " + ctx.request.body;
});
app.use(userRouter.routes());
app.use(userRouter.allowedMethods());
// 5.form-data
userRouter.post("/formdata", formParser.any(), (ctx, next) => {
ctx.body = "form-data " + ctx.request.body;
});
app.listen(6000, () => {
console.log("koa服务器启动成功");
});
上传文件中间件
上传文件,我们可以使用 koa 官网开发的第三方库:koa-multer
- npm install koa-multer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41const Koa = require("koa");
const KoaRouter = require("@koa/router");
const multer = require("@koa/multer");
const app = new Koa();
// const upload = multer({
// dest: './uploads'
// })
const upload = multer({
storage: multer.diskStorage({
destination(req, file, callback) {
callback(null, "./uploads");
},
filename(req, file, callback) {
callback(null, Date.now() + "_" + file.originalname);
},
}),
});
const uploadRouter = new KoaRouter({ prefix: "/upload" });
// 上传单文件: singer方法
uploadRouter.post("/avatar", upload.single("avatar"), (ctx, next) => {
console.log(ctx.request.file);
ctx.body = "文件上传成功";
});
// 上传多文件: array方法
uploadRouter.post("/photos", upload.array("photos"), (ctx, next) => {
console.log(ctx.request.files);
ctx.body = "文件上传成功";
});
app.use(uploadRouter.routes());
app.use(uploadRouter.allowedMethods());
app.listen(6000, () => {
console.log("koa服务器启动成功");
});
响应数据
输出结果:body 将响应主体设置为以下之一
- string :字符串数据
- Buffer :Buffer 数据
- Stream :流数据
- Object || Array:对象或者数组
- null :不输出任何内容
- 如果 response.status 尚未设置,Koa 会自动将状态设置为 200 或 204
请求状态:status
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40const fs = require("fs");
const Koa = require("koa");
const KoaRouter = require("@koa/router");
const app = new Koa();
const userRouter = new KoaRouter({ prefix: "/users" });
userRouter.get("/", (ctx, next) => {
// 1.body 的类型是 string
// ctx.body = 'user list data'
// 2.body 的类型是 Buffer
// ctx.body = Buffer.from('你好啊, 李银河')
// 3.body 的类型是 Stream
// const readStream = fs.createReadStream('./uploads/1668331072032_smile.png')
// ctx.type = 'image/jpeg'
// ctx.body = readStream
// 4.body 的类型是 数据 (array/object) => 使用最多
ctx.status = 201;
ctx.body = {
code: 0,
data: [
{ id: 111, name: "iphone", price: 100 },
{ id: 112, name: "xiaomi", price: 990 },
],
};
// 5.body 的类型是 null, 自动设置http status code为204
// ctx.body = null
});
app.use(userRouter.routes());
app.use(userRouter.allowedMethods());
app.listen(6000, () => {
console.log("koa服务器启动成功");
});
静态资源服务器
koa 并没有内置部署相关的功能,所以我们需要使用第三方库
1
npm install koa-static
部署的过程类似于 express
1
2
3
4
5
6
7
8
9
10
11const Koa = require("koa");
const static = require("koa-static");
const app = new Koa();
app.use(static("./uploads"));
app.use(static("./build"));
app.listen(8000, () => {
console.log("koa服务器启动成功");
});
服务端的错误处理
koa 中处理错误的方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44const Koa = require("koa");
const KoaRouter = require("@koa/router");
const app = new Koa();
const userRouter = new KoaRouter({ prefix: "/users" });
userRouter.get("/", (ctx, next) => {
const isAuth = false;
if (isAuth) {
ctx.body = "user list data";
} else {
// ctx.body = {code: -1003, message: '未授权的token, 请检测你的token'}
// EventEmitter
ctx.app.emit("error", -1003, ctx);
}
});
app.use(userRouter.routes());
app.use(userRouter.allowedMethods());
// 独立的文件: error-handle.js
app.on("error", (code, ctx) => {
const errCode = code;
let message = "";
switch (errCode) {
case -1001:
message = "账号或者密码错误";
break;
case -1002:
message = "请求参数不正确";
break;
case -1003:
message = "未授权, 请检查你的token信息";
break;
}
ctx.body = { code: errCode, message };
});
app.listen(6000, () => {
console.log("koa服务器启动成功");
});
express 和 koa 的区别
在学习了两个框架之后,我们应该已经可以发现 koa 和 express 的区别
从架构设计上来说
- express 是完整和强大的,其中帮助我们内置了非常多好用的功能
- koa 是简洁和自由的,它只包含最核心的功能,并不会对我们使用其他中间件进行任何的限制
- 甚至是在 app 中连最基本的 get、post 都没有给我们提供
- 我们需要通过自己或者路由来判断请求方式或者其他功能
因为 express 和 koa 框架他们的核心其实都是中间件
- 它们的中间件的执行机制是不同的,特别是针对某个中间件中包含异步操作时
- 所以,接下来,我们再来研究一下 express 和 koa 中间件的执行顺序问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32const express = require("express");
const axios = require("axios");
const app = express();
app.use(async (req, res, next) => {
console.log("express middleware 1");
req.msg = "aaa";
await next();
// 返回值结果
// res.json(req.msg)
});
app.use(async (req, res, next) => {
console.log("express middleware 2");
req.msg += "bbb";
await next();
});
// 执行异步代码
app.use(async (req, res, next) => {
console.log("express middleware 3");
const resData = await axios.get("http://123.207.32.32:8000/home/multidata");
req.msg += resData.data.data.banner.list[0].title;
// 只能在这里返回结果
res.json(req.msg);
});
app.listen(9000, () => {
console.log("express服务器启动成功");
});1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31const Koa = require("koa");
const axios = require("axios");
const app = new Koa();
app.use(async (ctx, next) => {
console.log("koa middleware 1");
ctx.msg = "aaa";
await next();
// 返回结果
ctx.body = ctx.msg;
});
app.use(async (ctx, next) => {
console.log("koa middleware 2");
ctx.msg += "bbb";
// 如果执行的下一个中间件是一个异步函数, 那么next默认不会等到中间件的结果, 就会执行下一步操作
// 如果我们希望等待下一个异步函数的执行结果, 那么需要在next函数前面加await
await next();
console.log("----");
});
app.use(async (ctx, next) => {
console.log("koa middleware 3");
const resData = await axios.get("http://123.207.32.32:8000/home/multidata");
ctx.msg += resData.data.data.banner.list[0].title;
});
app.listen(6000, () => {
console.log("koa服务器启动成功");
});
koa 洋葱模型
- 什么是 koa 洋葱模型?
- Koa 洋葱模型是一种中间件架构模式,基于此可以构建更加可维护和可扩展的 Web 应用程序
- 在 Koa 中,每个请求由一个或多个中间件处理,每个中间件都是一个函数,它可以读取和修改请求和响应对象,并且可以调用下一个中间件来处理请求和响应。 Koa 的中间件按照一定的顺序被串联在一起,称为洋葱模型
- 请求经过中间件层的处理,最终从最下层中间件处理完毕,然后从最上层中间件返回响应
什么是跨域?
- 要想理解跨域,要先理解浏览器的同源策略
- 同源策略是一个重要的安全策略,它用于限制一个 origin 的文档或者它加载的脚本如何能与另一个源的资源进行交互。它能帮助阻隔恶意文档,减少可能被攻击的媒介
- 如果两个 URL 的 protocol、port (en-US) (如果有指定的话) 和 host 都相同的话,则这两个 URL 是同源
- 这个方案也被称为 “协议/主机/端口元组”,或者直接是“元组”
- 事实上跨域的产生和前端分离的发展有很大的关系
- 早期的服务器端渲染的时候,是没有跨域的问题的
- 但是随着前后端的分离,目前前端开发的代码和服务器开发的 API 接口往往是分离的,甚至部署在不同的服务器上的
- 这个时候我们就会发现,访问 静态资源服务器 和 API 接口服务器 很有可能不是同一个服务器或者不是同一个端口
- 浏览器发现静态资源和 API 接口请求不是来自同一个地方时,就产生了跨域
- 所以,在静态资源服务器和API 服务器是同一台服务器时,是没有跨域问题的
跨域的解决方案总结
- 那么跨域问题如何解决呢?
- 所有跨域的解决方案几乎都和服务器有关系,单独的前端基本解决不了跨域(虽然网上也能看到各种方案,都是实际开发基本不会使用)
- 你说:老师,不对丫,我明明配置前端的 webpack 就可以解决跨域问题了
- webpack 配置的本质也是在 webpack-server 的服务器中配置了代理
- 跨域常见的解决方案
- 方案一:静态资源和 API 服务器部署在同一个服务器中
- 方案二:CORS, 即是指跨域资源共享
- 方案三:Node 代理服务器(开发)
- 方案四:Nginx 反向代理(部署)
- 不常见的方案
- jsonp:现在很少使用了(曾经流行过一段时间)
- postMessage:有兴趣了解一下吧
- websocket:为了解决跨域,所有的接口都变成 socket 通信?
CORS
跨源资源共享(CORS, Cross-Origin Resource Sharing 跨域资源共享)
- 它是一种基于 http header 的机制
- 该机制通过允许服务器标示除了它自己以外的其它源(域、协议和端口),使得浏览器允许这些 origin 访问加载自己的资源
浏览器将 CORS 请求分成两类:简单请求和非简单请求
只要同时满足以下两大条件,就属于简单请求(不满足就属于非简单请求)(了解即可)
请求方法是以下是三种方法之一
- HEAD
- GET
- POST
HTTP 的头信息不超出以下几种字段
- Accept
- Accept-Language
- Content-Language
- Last-Event-ID
- Content-Type:只限于三个值 application/x-www-form-urlencoded、multipart/form-data、text/plain
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40const Koa = require("koa");
const KoaRouter = require("@koa/router");
const app = new Koa();
app.use(async (ctx, next) => {
// 1.允许简单请求开启CORS
ctx.set("Access-Control-Allow-Origin", "*");
// 2.非简单请求开启下面的设置
ctx.set(
"Access-Control-Allow-Headers",
"Accept, AcceptEncoding, Connection, Host, Origin"
);
ctx.set("Access-Control-Allow-Credentials", true); // cookie
ctx.set(
"Access-Control-Allow-Methods",
"PUT, POST, GET, DELETE, PATCH, OPTIONS"
);
// 3.发起的是一个options请求
if (ctx.method === "OPTIONS") {
ctx.status = 204;
} else {
await next();
}
});
const userRouter = new KoaRouter({ prefix: "/users" });
userRouter.get("/list", (ctx, next) => {
ctx.body = [
{ id: 111, name: "strive", age: 18 },
{ id: 112, name: "张三", age: 20 },
{ id: 113, name: "李四", age: 22 },
];
});
app.use(userRouter.routes());
app.use(userRouter.allowedMethods());
app.listen(8000, () => console.log("koa服务器启动成功"));1
2
3
4
5
6<script>
fetch("http://localhost:8000/users/list").then(async (res) => {
const result = await res.json();
console.log(result);
});
</script>
Node 代理服务器
Node 代理服务器是平时开发中前端配置最多的一种方案
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// webpack ---> webpack-dev-server
const express = require("express");
const { createProxyMiddleware } = require("http-proxy-middleware");
const app = express();
app.use(express.static("../client")); // 静态资源 和 API服务器 部署在同一个服务器中
app.use(
"/api",
createProxyMiddleware({
target: "http://localhost:8000",
pathRewrite: { "^/api": "" },
})
);
app.listen(9000, () => console.log("express proxy服务器开启成功"));1
2
3
4
5
6
7<!-- 浏览器地址输入: http://localhost:9000 -->
<script>
fetch("http://localhost:9000/api/users/list").then(async (res) => {
const result = await res.json();
console.log(result);
});
</script>
Nginx 反向代理
下载 Nginx 地址:https://nginx.org/en/download.html
- 修改配置 conf/nginx.conf,然后重启
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23server {
listen 80;
server_name localhost;
location / {
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Headers "Accept,Accept-Encoding,Accept-Language,Connection,Content-Length,Content-Type,Host,Origin,Referer,User-Agent";
add_header Access-Control-Allow-Methods "GET,POST,PUT,OPTIONS";
add_header Access-Control-Allow-Credentials true;
if ($request_method = 'OPTIONS') {
return 204;
}
proxy_pass http://localhost:8000;
# root html;
# index index.html index.htm;
}
}1
2
3
4
5
6
7
8
9
10
11<!-- 浏览器地址输入: http://localhost -->
<!-- 需要这两行代码
const static = require('koa-static')
app.use(static('../client'))
-->
<script>
fetch("http://localhost/users/list").then(async (res) => {
const result = await res.json();
console.log(result);
});
</script>
webpack
路径模块
- path 模块用于对路径和文件进行处理,提供了很多好用的方法
- 我们知道在 Mac OS、Linux 和 window 上的路径时不一样的
- window 上会使用 \ 或者
\\来作为文件路径的分隔符,当然目前也支持 / - 在 Mac OS、Linux 的 Unix 操作系统上使用 / 来作为文件路径的分隔符
- window 上会使用 \ 或者
- 那么如果我们在 window 上使用 \ 来作为分隔符开发了一个应用程序,要部署到 Linux 上面应该怎么办呢?
- 显示路径会出现一些问题
- 所以为了屏蔽他们之间的差异,在开发中对于路径的操作我们可以使用 path 模块
- 可移植操作系统接口(英语:Portable Operating System Interface,缩写为 POSIX)
- Linux 和 Mac OS 都实现了 POSIX 接口
- Window 部分电脑实现了 POSIX 接口
常见的 API
从路径中获取信息
- dirname:获取文件的父文件夹
- basename:获取文件名
- extname:获取文件扩展名
1
2
3
4
5
6const path = require("path");
const filepath = "C://user/张三/test.txt";
console.log(path.extname(filepath)); // .txt
console.log(path.basename(filepath)); // test.txt
console.log(path.dirname(filepath)); // C://user/张三路径的拼接:path.join
- 如果我们希望将多个路径进行拼接,但是不同的操作系统可能使用的是不同的分隔符
- 这个时候我们可以使用 path.join 函数
1
2
3
4
5
6
7const path = require("path");
const path1 = "/目录一/目录二";
const path2 = "./目录三/目录四/test.txt";
const path3 = "../目录三/目录四/demo.txt";
console.log(path.join(path1, path2)); // \目录一\目录二\目录三\目录四\test.txt
console.log(path.join(path1, path3)); // \目录一\目录三\目录四\demo.txt拼接绝对路径:path.resolve
- path.resolve() 方法会把一个路径或路径片段的序列解析为一个绝对路径
- 给定的路径的序列是从右往左被处理的,后面每个 path 被依次解析,直到构造完成一个绝对路径
- 如果在处理完所有给定 path 的段之后,还没有生成绝对路径,则使用当前工作目录
- 生成的路径被规范化并删除尾部斜杠,零长度 path 段被忽略
- 如果没有 path 传递段,path.resolve() 将返回当前工作目录的绝对路径
1
2
3
4
5
6
7
8
9
10// path模块的使用/index.js
const path = require("path");
console.log(
path.resolve("./目录一/目录二", "../目录三/目录四", "./demo.txt")
);
// G:\学习资料\Node+Webpack\基础\代码\Path模块的使用\目录一\目录三\目录四\demo.txt
console.log(path.resolve());
// G:\学习资料\Node+Webpack\基础\代码\Path模块的使用
认识 webpack
- 事实上随着前端的快速发展,目前前端的开发已经变的越来越复杂了
- 比如开发过程中我们需要通过模块化的方式来开发
- 比如也会使用一些高级的特性来加快我们的开发效率或者安全性,比如通过 ES6+、TypeScript 开发脚本逻辑,通过 sass、less 等方式来编写 css 样式代码
- 比如开发过程中,我们还希望实时的监听文件的变化来并且反映到浏览器上,提高开发的效率
- 比如开发完成后我们还需要将代码进行压缩、合并以及其他相关的优化
- 但是对于很多的前端开发者来说,并不需要思考这些问题,日常的开发中根本就没有面临这些问题
- 这是因为目前前端开发我们通常都会直接使用三大框架来开发:Vue、React、Angular
- 但是事实上,这三大框架的创建过程我们都是借助于脚手架(CLI)的
- 事实上 Vue-CLI、create-react-app、Angular-CLI 都是基于 webpack来帮助我们支持模块化、less、TypeScript、打包优化等的
webpack 到底是什么呢?
- 我们先来看一下官方的解释
- webpack is a static module bundler for modern JavaScript applications
- webpack 是一个静态的模块化打包工具,为现代的 JavaScript 应用程序。它将根据模块的依赖关系进行静态分析,然后将这些模块按照指定的规则生成对应的静态资源
- 我们来对上面的解释进行拆解
- 打包(bundler):webpack 可以帮助我们进行打包,所以它是一个打包工具
- 静态的(static):这样表述的原因是我们最终可以将代码打包成最终的静态资源(部署到静态服务器)
- 模块化(module):webpack 默认支持各种模块化开发,ES Module、CommonJS、AMD 等
- 现代的(modern):因为现代前端开发面临各种各样的问题,才催生了 webpack 的出现和发展
webpack 的使用前提
- webpack 的官方文档是https://webpack.js.org
- webpack 的中文官方文档是https://webpack.docschina.org
- DOCUMENTATION:文档详情,也是我们最关注的
- Webpack 的运行是依赖Node 环境的,所以我们电脑上必须有 Node 环境
- 所以我们需要先安装 Node.js,并且同时会安装 npm
- 我当前电脑上的 node 版本是 v16.16.0,npm 版本是 8.11.0(你也可以使用 nvm 或者 n 来管理 Node 版本)
- Node 官方网站:https://nodejs.org
webpack 的安装
webpack 的安装目前分为两个:webpack、webpack-cli
那么它们是什么关系呢?
- 执行 webpack 命令,会执行 node_modules 下的.bin 目录下的 webpack
- webpack 在执行时是依赖 webpack-cli 的,如果没有安装就会报错
- 而 webpack-cli 中代码执行时,才是真正利用 webpack 进行编译和打包的过程
- 所以在安装 webpack 时,我们需要同时安装 webpack-cli(第三方的脚手架事实上是没有使用 webpack-cli 的,而是类似于自己的 vue-service-cli 的东西)
1
2npm install webpack webpack-cli -g # 全局安装
npm install webpack webpack-cli -D # 局部安装
webpack 的默认打包
我们可以通过 webpack 进行打包,之后运行打包之后的代码
1
2
3
4
5
6
7
8
9
10
11// src/index.js
const message = "Hello World";
const foo = (num1, num2) => {
console.log(num1 + num2);
};
foo(10, 20);
foo(20, 30);
foo(30, 40);
console.log(message.length);- 在目录下直接执行 webpack 命令
- webpack
- 在目录下直接执行 webpack 命令
生成一个 dist 文件夹,里面存放一个 main.js 的文件,就是我们打包之后的文件
- 这个文件中的代码被压缩和丑化了
- 另外我们发现代码中依然存在 ES6 的语法,比如箭头函数、const 等,这是因为默认情况下 webpack 并不清楚我们打包后的文件是否需要转成 ES5 之前的语法,后续我们需要通过 babel 来进行转换和设置
1
2
3
4
5
6(() => {
const o = (o, l) => {
console.log(o + l);
};
o(10, 20), o(20, 30), o(30, 40), console.log("Hello World".length);
})();我们发现是可以正常进行打包的,但是有一个问题,webpack 是如何确定我们的入口的呢?
- 事实上,当我们运行 webpack 时,webpack 会查找当前目录下的 src/index.js 作为入口
- 所以,如果当前项目中没有存在 src/index.js 文件,那么会报错
当然,我们也可以通过配置来指定入口和出口
1
npx webpack --entry ./src/main.js --output-path ./build
创建局部的 webpack
前面我们直接执行 webpack 命令使用的是全局的 webpack,如果希望使用局部的可以按照下面的步骤来操作
第一步:创建 package.json 文件,用于管理项目的信息、库依赖等
- npm init -y
第二步:安装局部的 webpack
- npm install webpack webpack-cli -D
第三步:使用局部的 webpack
- npx webpack
第四步:在 package.json 中创建 scripts 脚本,执行脚本打包即可
1
2
3"scripts": {
"build": "webpack"
}
webpack 配置文件
在通常情况下,webpack 需要打包的项目是非常复杂的,并且我们需要一系列的配置来满足要求,默认配置必然是不可以的
我们可以在根目录下创建一个 webpack.config.js 文件,来作为 webpack 的配置文件
1
2
3
4
5
6
7
8
9const path = require("path");
module.exports = {
entry: "./src/index.js",
output: {
filename: "bundle.js",
path: path.resolve(__dirname, "./build"),
},
};
指定配置文件
如果我们的配置文件并不是 webpack.config.js 的名字,而是其他的名字呢
- 比如我们将 webpack.config.js 修改成了 wk.config.js
- 这个时候我们可以通过 --config 来指定对应的配置文件
1
webpack --config wk.config.js
但是每次这样执行命令来对源码进行编译,会非常繁琐,所以我们可以在 package.json 中增加一个新的脚本
1
2
3"scripts": {
"build": "webpack --config wk.config.js"
}
webpack 的依赖图
webpack 到底是如何对我们的项目进行打包的呢
- 事实上 webpack 在处理应用程序时,它会根据命令或者配置文件找到入口文件
- 从入口开始,会生成一个 依赖关系图,这个依赖关系图会包含应用程序中所需的所有模块(比如.js 文件、css 文件、图片、字体等)
- 然后遍历图结构,打包一个个模块(根据文件的不同使用不同的 loader 来解析)

编写案例代码
我们创建一个 component.js
- 通过 JavaScript 创建了一个元素,并且希望给它设置一些样式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// src/component.js
import "./css/style.css"; // .content { color: red; }
const divEl = document.createElement("div");
divEl.textContent = "Hello World";
divEl.classList.add("content");
document.body.append(divEl);
// src/index.js
import "./component.js";
// npm run build
// ERROR in ./src/css/style.css 1:0
// Module parse failed: Unexpected token (1:0)
// You may need an appropriate loader to handle this file type, ....
css-loader
- 上面的错误信息告诉我们需要一个 loader 来加载这个 css 文件,但是loader是什么呢?
- loader 可以用于对模块的源代码进行转换
- 我们可以将 css 文件也看成是一个模块,我们是通过 import 来加载这个模块的
- 在加载这个模块时,webpack 其实并不知道如何对其进行加载,我们必须制定对应的 loader 来完成这个功能
- 那么我们需要一个什么样的 loader 呢?
- 对于加载 css 文件来说,我们需要一个可以读取 css 文件的 loader
- 这个 loader 最常用的是css-loader
- css-loader 的安装:npm install css-loader -D
使用方案
如何使用这个 loader 来加载 css 文件呢?有三种方式
- 内联方式
- CLI 方式(webpack5 中不再使用)
- 配置方式
内联方式:内联方式使用较少,因为不方便管理
- 在引入的样式前加上使用的 loader,并且使用 ! 分割
1
import "css-loader!./css/style.css";
CLI 方式
- 在 webpack5 的文档中已经没有了–module-bind
- 实际应用中也比较少使用,因为不方便管理
loader 配置方式
配置方式表示的意思是在我们的 webpack.config.js 文件中写明配置信息
- module.rules 中允许我们配置多个 loader(因为我们也会继续使用其他的 loader,来完成其他文件的加载)
- 这种方式可以更好的表示 loader 的配置,也方便后期的维护,同时也让你对各个 Loader 有一个全局的概览
module.rules 的配置如下
rules 属性对应的值是一个数组:[Rule]
数组中存放的是一个个的 Rule,Rule 是一个对象,对象中可以设置多个属性
- test 属性:用于对 resource(资源)进行匹配的,通常会设置成正则表达式
- use 属性:对应的值时一个数组:[UseEntry]
- UseEntry 是一个对象,可以通过对象的属性来设置一些其他属性
- loader:必须有一个 loader 属性,对应的值是一个字符串
- options:可选的属性,值是一个字符串或者对象,值会被传入到 loader 中
- query:目前已经使用 options 来替代
- UseEntry 是一个对象,可以通过对象的属性来设置一些其他属性
注意:因为 loader 的执行顺序是从右向左(或者说从下到上,或者说从后到前的)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23const path = require("path");
module.exports = {
entry: "./src/index.js",
output: {
filename: "bundle.js",
path: path.resolve(__dirname, "./build"),
},
module: {
rules: [
{
// 告诉 webpack 匹配什么文件
test: /\.css$/,
use: [{ loader: "css-loader" }],
// 简写一: 如果 loader 只有一个
// loader: "css-loader"
// 简写二: 多个 loader 不需要其他属性时, 可以直接写 loader 字符串形式
// use: ["css-loader", "xxx-loader", "xxx-loader"],
},
],
},
};1
2
3
4
5
6
7
8<!-- src/index.html -->
<html lang="zh">
<head></head>
<body>
<script src="../build/bundle.js"></script>
</body>
</html>
style-loader
我们已经可以通过 css-loader 来加载 css 文件了
- 但是你会发现这个 css 在我们的代码中并没有生效(页面没有效果)
这是为什么呢?
- 因为 css-loader 只是负责将.css 文件进行解析,并不会将解析之后的css 插入到页面中
- 如果我们希望再完成插入 style 的操作,那么我们还需要另外一个 loader,就是style-loader
安装 style-loader:npm install style-loader -D
1
use: ["style-loader", "css-loader"];
注意:因为 loader 的执行顺序是从右向左(或者说从下到上,或者说从后到前的),所以我们需要将 style-loader 写到 css-loader 的前面
认识 PostCSS 工具
什么是 PostCSS 呢?
- PostCSS 是一个通过 JavaScript 来转换样式的工具
- 这个工具可以帮助我们进行一些 CSS 的转换和适配,比如自动添加浏览器前缀、css 样式的重置
- 但是实现这些功能,我们需要借助于 PostCSS 对应的插件
如何使用 PostCSS 呢?主要就是两个步骤
- 第一步:查找 PostCSS 在构建工具中的扩展,比如 webpack 中的 postcss-loader
- 第二步:选择可以添加你需要的 PostCSS 相关的插件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// npm install postcss-loader -D
use: [
{
// 注意:因为 postcss 需要有对应的插件才会起效果,所以我们需要配置它的 plugin
loader: "postcss-loader",
options: {
postcssOptions: {
// 因为我们需要添加前缀,所以要安装 autoprefixer:npm install autoprefixer -D
plugins: ["autoprefixer"],
},
},
},
],
use: ["postcss-loader"]
// 我们可以将这些配置信息放到一个单独的文件中进行管理
// 在根目录下创建 postcss.config.js
module.exports = {
plugins: ["autoprefixer"],
};
postcss-preset-env
事实上,在配置 postcss-loader 时,我们配置插件并不需要使用 autoprefixer
我们可以使用另外一个插件:postcss-preset-env
- postcss-preset-env 也是一个 postcss 的插件
- 它可以帮助我们将一些现代的 CSS 特性,转成大多数浏览器认识的 CSS,并且会根据目标浏览器或者运行时环境添加所需的 polyfill
- 也包括会自动帮助我们添加 autoprefixer(所以相当于已经内置了 autoprefixer)
首先,我们需要安装:npm install postcss-preset-env -D
之后,我们直接修改掉之前的 autoprefixer 即可
1
2
3
4// postcss.config.js
module.exports = {
plugins: ["postcss-preset-env"],
};
认识 asset module type
我们当前使用的 webpack 版本是 webpack5
- 在 webpack5 之前,加载这些资源我们需要使用一些 loader,比如 raw-loader 、url-loader、file-loader
- 在 webpack5 开始,我们可以直接使用资源模块类型(asset module type),来替代上面的这些 loader
资源模块类型(asset module type),通过添加 4 种新的模块类型,来替换所有这些 loader
- asset/resource 发送一个单独的文件并导出 URL
- 之前通过使用 file-loader 实现
- asset/inline 导出一个资源的 data URI
- 之前通过使用 url-loader 实现
- asset/source 导出资源的源代码
- 之前通过使用 raw-loader 实现
- asset 在导出一个 data URI 和发送一个单独的文件之间自动选择
- 之前通过使用 url-loader,并且配置资源体积限制实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32module: {
rules: [
{
test: /\.(png|jpe?g|svg|gif)$/i,
// 1.打包两张图片, 并且这两张图片有自己的地址, 将地址设置到img/background-image中
// 缺点: 多图片加载的两次网络请求
// type: "asset/resource",
// 2.将图片进行base64的编码, 并且直接将编码后的源码放到打包的js文件中
// 缺点: 造成js文件非常大, 下载js文件本身消耗时间非常长, 造成js代码的下载和解析/执行时间过长
// type: "asset/inline"
// 3.合理的规范:
// 3.1.对于小一点的图片, 可以进行base64编码
// 3.2.对于大一点的图片, 单独的图片打包, 形成url地址, 单独的请求这个url图片
type: "asset",
parser: {
dataUrlCondition: {
// 1kb === 1024字节
maxSize: 60 * 1024, // 60kb
},
},
generator: {
// 占位符
// name: 指向原来的图片名称
// ext: 扩展名
// hash: 使用MD4的散列函数处理,生成的一个128位的hash值(32个十六进制)
filename: "img/[name]_[hash:8][ext]",
},
},
];
}- asset/resource 发送一个单独的文件并导出 URL
为什么需要 babel?
- 事实上,在开发中我们很少直接去接触 babel,但是 babel 对于前端开发来说,目前是不可缺少的一部分
- 开发中,我们想要使用ES6+的语法,想要使用TypeScript,开发React 项目,它们都是离不开 Babel 的
- 所以,学习 Babel对于我们理解代码从编写到线上的转变过程至关重要
- 那么,Babel 到底是什么呢?
- Babel 是一个工具链,主要用于旧浏览器或者环境中将 ECMAScript 2015+代码转换为向后兼容版本的 JavaScript,但 Babel 在进行代码转换时是需要依赖对应的插件来转换
- 包括:语法转换、源代码转换等
命令行使用
babel 本身可以作为一个独立的工具(和 postcss 一样),不和 webpack 等构建工具配置来单独使用
如果我们希望在命令行尝试使用 babel,需要安装如下库
- @babel/core:babel 的核心代码,必须安装
- @babel/cli:可以让我们在命令行使用 babel
1
npm install @babel/cli @babel/core -D
使用 babel 来处理我们的源代码
- src:是源文件的目录
- –out-dir:指定要输出的文件夹 dist
1
npx babel src ./src/index.js --out-dir dist
插件的使用
比如我们需要转换箭头函数,那么我们就可以使用箭头函数转换相关的插件
1
2
3npm install @babel/plugin-transform-arrow-functions -D
npx babel src --out-dir dist --plugins=@babel/plugin-transform-arrow-functions查看转换后的结果:我们会发现 const 并没有转成 var
- 这是因为 plugin-transform-arrow-functions,并没有提供这样的功能
- 我们需要使用 plugin-transform-block-scoping 来完成这样的功能
1
2
3npm install @babel/plugin-transform-block-scoping -D
npx babel src --out-dir dist --plugins=@babel/plugin-transform-block-scoping,@babel/plugin-transform-arrow-functions
预设
但是如果要转换的内容过多,一个个设置是比较麻烦的,我们可以使用预设(preset)
安装@babel/preset-env 预设
1
npm install @babel/preset-env -D
执行如下命令
1
npx babel src --out-dir dist --presets=@babel/preset-env
底层原理
- babel 是如何做到将我们的一段代码(ES6、TypeScript、React)转成另外一段代码(ES5)的呢?
- 从一种源代码(原生语言)转换成另一种源代码(目标语言),这是什么的工作呢?
- 就是编译器,事实上我们可以将 babel 看成就是一个编译器
- Babel 编译器的作用就是将我们的源代码,转换成浏览器可以直接识别的另外一段源代码
- Babel 也拥有编译器的工作流程
- 解析阶段(Parsing)
- 转换阶段(Transformation)
- 生成阶段(Code Generation)
- https://github.com/jamiebuilds/the-super-tiny-compiler
编译器执行原理
babel 的执行阶段
当然,这只是一个简化版的编译器工具流程,在每个阶段又会有自己具体的工作

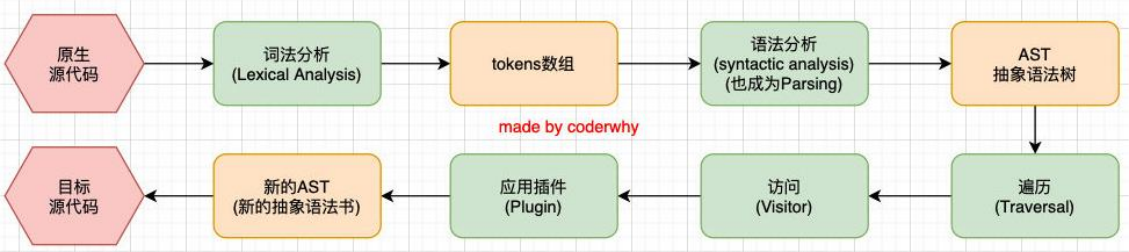
babel-loader
在实际开发中,我们通常会在构建工具中通过配置 babel 来对其进行使用的,比如在 webpack 中
那么我们就需要去安装相关的依赖
- 如果之前已经安装了@babel/core,那么这里不需要再次安装
1
npm install babel-loader @babel/core -D
我们可以设置一个规则,在加载 js 文件时,使用我们的 babel
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16{
test: /\.js$/,
use: {
loader: "babel-loader",
// 我们必须指定使用的插件才会生效
options: {
plugins: ["@babel/plugin-transform-block-scoping","@babel/plugin-transform-arrow-functions"],
},
},
},
use: ["babel-loader"]
// babel.config.js
module.exports = {
plugins: ["@babel/plugin-transform-block-scoping","@babel/plugin-transform-arrow-functions"],
};
babel-preset
如果我们一个个去安装使用插件,那么需要手动来管理大量的 babel 插件,我们可以直接给 webpack 提供一个 preset,webpack 会根据我们的预设来加载对应的插件列表,并且将其传递给 babel
比如常见的预设有三个
- env
- react
- TypeScript
安装 preset-env
1
npm install @babel/preset-env
1
2
3
4
5
6
7
8
9{
test: /\.js$/,
use: {
loader: "babel-loader",
options: {
presets: ["@babel/preset-env"]
},
},
},
浏览器兼容性
我们来思考一个问题:开发中,浏览器的兼容性问题,我们应该如何去解决和处理?
- 当然这个问题很笼统,这里我说的兼容性问题不是指屏幕大小的变化适配
- 我这里指的兼容性是针对不同的浏览器支持的特性:比如 css 特性、js 语法之间的兼容性
我们知道市面上有大量的浏览器
- 有 Chrome、Safari、IE、Edge、Chrome for Android、UC Browser、QQ Browser 等等
- 它们的市场占率是多少?我们要不要兼容它们呢?
其实在很多的脚手架配置中,都能看到类似于这样的配置信息
- 这里的百分之一,就是指市场占有率
1
2
3> 1%
last 2 versions
not dead
浏览器市场占有率
- 但是在哪里可以查询到浏览器的市场占有率呢?
- 这个最好用的网站,也是我们工具通常会查询的一个网站就是 caniuse
- https://caniuse.com/usage-table
browserslist 工具
- 但是有一个问题,我们如何可以在 css 兼容性和 js 兼容性下共享我们配置的兼容性条件呢?
- 就是当我们设置了一个条件: > 1%
- 我们表达的意思是css 要兼容市场占有率大于 1%的浏览器,js 也要兼容市场占有率大于 1%的浏览器
- 如果我们是通过工具来达到这种兼容性的,比如我们讲到的 postcss-preset-env、babel、autoprefixer等
- 如何可以让他们共享我们的配置呢?
- 这个问题的答案就是Browserslist
- Browserslist 是什么?Browserslist 是一个在不同的前端工具之间,共享目标浏览器和 Node.js 版本的配置
浏览器查询过程
我们可以编写类似于这样的配置
1
2
3> 1%
last 2 versions
not dead那么之后,这些工具会根据我们的配置来获取相关的浏览器信息,以方便决定是否需要进行兼容性的支持
- 条件查询使用的是 caniuse-lite 的工具,这个工具的数据来自于 caniuse 的网站上
browserslist 编写规则
规则一
- 那么在开发中,我们可以编写的条件都有哪些呢?(加粗部分是最常用的)
- defaults:Browserslist 的默认浏览器(> 0.5%, last 2 versions, Firefox ESR, not dead)
- 5%:通过全局使用情况统计信息选择的浏览器版本。 >=,<和<=工作过
- 5% in US:使用美国使用情况统计信息。它接受两个字母的国家/地区代码
- 5% in alt-AS:使用亚洲地区使用情况统计信息。有关所有区域代码的列表,请参见 caniuse-lite/data/regions
- 5% in my stats:使用自定义用法数据
- 5% in browserslist-config-mycompany stats:使用 来自的自定义使用情况数据 browserslist-config-mycompany/browserslist-stats.json
- cover 99.5%:提供覆盖率的最受欢迎的浏览器
- cover 99.5% in US:与上述相同,但国家/地区代码由两个字母组成
- cover 99.5% in my stats:使用自定义用法数据
- dead:24 个月内没有官方支持或更新的浏览器。现在是 IE 10,IE_Mob 11,BlackBerry 10,BlackBerry 7, Samsung 4 和 OperaMobile 12.1
- last 2 versions:每个浏览器的最后 2 个版本
- last 2 Chrome versions:最近 2 个版本的 Chrome 浏览器
- last 2 major versions 或 last 2 iOS major versions:最近 2 个主要版本的所有次要/补丁版本
规则二
- node 10 和 node 10.4:选择最新的 Node.js10.x.x 或 10.4.x 版本
- current node:Browserslist 现在使用的 Node.js 版本
- maintained node versions:所有 Node.js 版本,仍由 Node.js Foundation 维护
- iOS 7:直接使用 iOS 浏览器版本 7
- Firefox > 20:Firefox 的版本高于 20 >=,<并且<=也可以使用。它也可以与 Node.js 一起使用
- ie 6-8:选择一个包含范围的版本
- Firefox ESR:最新的[Firefox ESR]版本
- PhantomJS 2.1 和 PhantomJS 1.9:选择类似于 PhantomJS 运行时的 Safari 版本
- extends browserslist-config-mycompany:从 browserslist-config-mycompanynpm 包中查询
- supports es6-module:支持特定功能的浏览器
- es6-module 这是“我可以使用” 页面 feat 的 URL 上的参数。有关所有可用功能的列表,请参见 。caniuse-lite/data/features
- browserslist config:在 Browserslist 配置中定义的浏览器。在差异服务中很有用,可用于修改用户的配置,例如 browserslist config and supports es6-module
- since 2015 或 last 2 years:自 2015 年以来发布的所有版本(since 2015-03 以及 since 2015-03-10)
- unreleased versions 或 unreleased Chrome versions:Alpha 和 Beta 版本
- not ie <= 8:排除先前查询选择的浏览器
- node 10 和 node 10.4:选择最新的 Node.js10.x.x 或 10.4.x 版本
命令行使用 browserslist
我们可以直接通过命令来查询某些条件所匹配到的浏览器
1
npx browserslist ">1%, last 2 version, not dead"
配置 browserslist
我们如何可以配置 browserslist 呢?两种方案
- 方案一:在 package.json 中配置
- 方案二:单独的一个配置文件.browserslistrc 文件
方案一:package.json 配置
1
2
3
4
5"browserslist":[
"> 0.2%",
"last 2 versions",
"not dead"
]方案二:.browserslistrc 文件
1
2
3> 0.2%
last 2 versions
not dead如果没有配置,那么也会有一个默认配置
1
2
3
4
5
6browserslist.defaults = [
"> 0.5%",
"last 2 versions",
"Firefox ESR",
"not dead",
];
设置目标浏览器
我们最终打包的 JavaScript 代码,是需要跑在目标浏览器上的,那么如何告知 babel 我们的目标浏览器呢?
- browserslist 工具
- target 属性
我们也可以通过 targets 来进行配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18{
test: /\.js$/,
use: {
loader: "babel-loader",
options: {
presets: [
[
"@babel/preset-env",
{
// 在开发中针对babel的浏览器兼容查询使用browserslist工具, 而不是设置target
// 因为browserslist工具, 可以在多个前端工具之间进行共享浏览器兼容性(postcss/babel)
targets: "> 2%"
},
],
],
},
},
}那么,如果两个同时配置了,哪一个会生效呢?
- 配置的 targets 属性会覆盖 browserslist
- 但是在开发中,更推荐通过 browserslist 来配置,因为类似于 postcss 工具,也会使用 browserslist,进行统一浏览器的适配
Stage-X 的预设
- 要了解 Stage-X,我们需要先了解一下 TC39 的组织
- TC39 是指技术委员会(Technical Committee)第 39 号
- 它是 ECMA 的一部分,ECMA 是 “ECMAScript” 规范下的 JavaScript 语言标准化的机构
- ECMAScript 规范定义了 JavaScript 如何一步一步的进化、发展
- TC39 遵循的原则是:分阶段加入不同的语言特性,新流程涉及四个不同的 Stage
- Stage 0:strawman(稻草人),任何尚未提交作为正式提案的讨论、想法变更或者补充都被认为是第 0 阶段的"稻草人"
- Stage 1:proposal(提议),提案已经被正式化,并期望解决此问题,还需要观察与其他提案的相互影响
- Stage 2:draft(草稿),Stage 2 的提案应提供规范初稿、草稿。此时,语言的实现者开始观察 runtime 的具体实现是否合理
- Stage 3:candidate(候补),Stage 3 提案是建议的候选提案。在这个高级阶段,规范的编辑人员和评审人员必须在最终规范上签字。Stage 3 的提案不会有太大的改变,在对外发布之前只是修正一些问题
- Stage 4:finished(完成),进入 Stage 4 的提案将包含在 ECMAScript 的下一个修订版中
babel 的 Stage-X 设置
在 babel7 之前(比如 babel6 中),我们会经常看到这种设置方式
它表达的含义是使用对应的 babel-preset-stage-x 预设
但是从 babel7 开始,已经不建议使用了,建议使用 preset-env 来设置
1
2
3
4// babel.config.js
module.exports = {
presets: ["stage-0"],
};
babel 的配置文件
像之前一样,我们可以将 babel 的配置信息放到一个独立的文件中,babel 给我们提供了两种配置文件的编写
- babel.config.json(或者.js,.cjs,.mjs)文件
- .babelrc.json(或者.babelrc,.js,.cjs,.mjs)文件
它们两个有什么区别呢?目前很多的项目都采用了多包管理的方式(babel 本身、element-plus、umi 等)
- .babelrc.json:早期使用较多的配置方式,但是对于配置 Monorepos 项目是比较麻烦的
- babel.config.json(babel7):可以直接作用于 Monorepos 项目的子包,更加推荐
1
2
3
4// babel.config.js
module.exports = {
presets: [["@babel/preset-env", { targets: "> 2%" }]],
};
认识 polyfill
- Polyfill 是什么呢?
- 翻译:一种用于衣物、床具等的聚酯填充材料, 使这些物品更加温暖舒适
- 理解:更像是应该填充物(垫片),一个补丁,可以帮助我们更好的使用 JavaScript
- 为什么时候会用到 polyfill 呢?
- 比如我们使用了一些语法特性(例如:Promise, Generator, Symbol 等以及实例方法例如 Array.prototype.includes 等)
- 但是某些浏览器压根不认识这些特性,必然会报错
- 我们可以使用 polyfill 来填充或者说打一个补丁,那么就会包含该特性了
如何使用 polyfill
babel7.4.0 之前,可以使用 @babel/polyfill 的包,但是该包现在已经不推荐使用了
babel7.4.0 之后,可以通过单独引入 core-js 和 regenerator-runtime 来完成 polyfill 的使用
1
npm install core-js regenerator-runtime --save
配置 babel.config.js
- 我们需要在 babel.config.js 文件中进行配置,给 preset-env 配置一些属性
- useBuiltIns:设置以什么样的方式来使用 polyfill
- corejs:设置 corejs 的版本,目前使用较多的是 3.x 的版本,比如我使用的是 3.8.x 的版本
- 另外 corejs 可以设置是否对提议阶段的特性进行支持
- 设置 proposals 属性为 true 即可
useBuiltIns 属性设置
useBuiltIns 属性有三个常见的值
第一个值:false
- 打包后的文件不使用 polyfill 来进行适配
- 并且这个时候是不需要设置 corejs 属性的
第二个值:usage
- 会根据源代码中出现的语言特性,自动检测所需要的 polyfill
- 这样可以确保最终包里的 polyfill 数量的最小化,打包的包相对会小一些
- 可以设置 corejs 属性来确定使用的 corejs 的版本
1
2
3presets: [
["@babel/preset-env", { corejs: 3, useBuiltIns: "usage" }],
],第三个值:entry
如果我们依赖的某一个库本身使用了某些 polyfill 的特性,但是因为我们使用的是 usage,所以之后用户浏览器可能会报错
所以,如果你担心出现这种情况,可以使用 entry
并且需要在入口文件中添加
import 'core-js/stable'; import 'regenerator-runtime/runtime'这样做会根据 browserslist 目标导入所有的 polyfill,但是对应的包也会变大
React 的 jsx 支持
在我们编写 react 代码时,react 使用的语法是 jsx,jsx 是可以直接使用 babel 来转换的
对 react jsx 代码进行处理需要如下的插件
- @babel/plugin-syntax-jsx
- @babel/plugin-transform-react-jsx
- @babel/plugin-transform-react-display-name
但是开发中,我们并不需要一个个去安装这些插件,我们依然可以使用 preset 来配置
1
npm install @babel/preset-react -D
1
presets: [["@babel/preset-env", {}], ["@babel/preset-react"]],
TypeScript 的编译
在项目开发中,我们会使用 TypeScript 来开发,那么 TypeScript 代码是需要转换成 JavaScript 代码
可以通过 TypeScript 的 compiler 来转换成 JavaScript
1
npm install typescript -D
另外 TypeScript 的编译配置信息我们通常会编写一个 tsconfig.json 文件
1
tsc --init
之后我们可以运行 npx tsc 来编译自己的 ts 代码
1
npx tsc
使用 ts-loader
如果我们希望在 webpack 中使用 TypeScript,那么我们可以使用 ts-loader 来处理 ts 文件
1
npm install ts-loader -D
配置 ts-loader
1 | { |
- 之后,我们通过 npm run build 打包即可
使用 babel-loader
除了可以使用 TypeScript Compiler 来编译 TypeScript 之外,我们也可以使用 Babel
- Babel 是有对 TypeScript 进行支持
- 我们可以使用插件: @babel/tranform-typescript
- 但是更推荐直接使用 preset:@babel/preset-typescript
我们来安装@babel/preset-typescript
1
npm install @babel/preset-typescript -D
1
2
3
4
5
6
7
8
9{ test: /\.ts$/, use: "babel-loader" }
// babel.config.js
module.exports = {
presets: [
["@babel/preset-env", {}],
["@babel/preset-typescript"],
],
};
ts-loader 和 babel-loader 选择
- 那么我们在开发中应该选择 ts-loader 还是 babel-loader 呢?
- 使用 ts-loader(TypeScript Compiler)
- 来直接编译 TypeScript,那么只能将 ts 转换成 js
- 如果我们还希望在这个过程中添加对应的 polyfill,那么 ts-loader 是无能为力的
- 我们需要借助于 babel 来完成 polyfill 的填充功能
- 使用 babel-loader(Babel)
- 来直接编译 TypeScript,也可以将 ts 转换成 js,并且可以实现 polyfill 的功能
- 但是 babel-loader 在编译的过程中,不会对类型错误进行检测
- 那么在开发中,我们如何可以同时保证两个情况都没有问题呢?
编译 TypeScript 最佳实践
- 事实上 TypeScript 官方文档有对其进行说明
- 也就是说我们使用 Babel 来完成代码的转换,使用 tsc 来进行类型的检查
- 但是,如何可以使用 tsc 来进行类型的检查呢?
- 在这里,我在 scripts 中添加了两个脚本,用于类型检查
- 我们执行 npm run type-check 可以对 ts 代码的类型进行检测
- 我们执行 npm run type-check-watch 可以实时的检测类型错误
resolve 模块解析
resolve 用于设置模块如何被解析
- 在开发中我们会有各种各样的模块依赖,这些模块可能来自于自己编写的代码,也可能来自第三方库
- resolve 可以帮助 webpack 从每个 require/import 语句中,找到需要引入的模块代码
- webpack 使用 enhanced-resolve 来解析文件路径
webpack 能解析三种文件路径
- 绝对路径
- 由于已经获得文件的绝对路径,因此不需要再做进一步解析
- 相对路径
- 在这种情况下,使用 import 或 require 的资源文件所处的目录,被认为是上下文目录
- 在 import/require 中给定的相对路径,会拼接此上下文路径,来生成模块的绝对路径
- 模块路径
- 在 resolve.modules 中指定的所有目录检索模块。
- 默认值是 [‘node_modules’],所以默认会从 node_modules 中查找文件
- 我们可以通过设置别名的方式来替换初识模块路径
- 在 resolve.modules 中指定的所有目录检索模块。
- 绝对路径
如果是一个文件
- 如果文件具有扩展名,则直接打包文件
- 否则,将使用 resolve.extensions 选项作为文件扩展名解析
如果是一个文件夹
- 会在文件夹中根据 resolve.mainFiles 配置选项中指定的文件顺序查找
- resolve.mainFiles 的默认值是 [‘index’]
- 再根据 resolve.extensions 来解析扩展名
- 会在文件夹中根据 resolve.mainFiles 配置选项中指定的文件顺序查找
extensions 和 alias 配置
extensions 是解析到文件时自动添加扩展名
- 默认值是 [‘.wasm’, ‘.mjs’, ‘.js’, ‘.json’]
- 所以如果我们代码中想要添加加载 .vue 或者 jsx 或者 ts 等文件时,我们必须自己写上扩展名
另一个非常好用的功能是配置别名 alias
- 特别是当我们项目的目录结构比较深的时候,或者一个文件的路径可能需要 …/…/…/这种路径片段
- 我们可以给某些常见的路径起一个别名
1
2
3
4
5
6resolve: {
extensions: [".js", ".json", ".vue", ".jsx", ".ts", ".tsx"],
alias: {
utils: path.resolve(__dirname, "./src/utils")
}
}
认识 Plugin
- Webpack 的另一个核心是 Plugin,官方有这样一段对 Plugin 的描述
- While loaders are used to transform certain types of modules, plugins can be leveraged to perform a wider range of tasks like bundle optimization, asset management and injection of environment variables
- 上面表达的含义翻译过来就是
- Loader 是用于特定的模块类型进行转换
loader本质就是一个函数,在该函数中对接收到的内容进行转换,返回转换后的结果。因为 Webpack 只认识 JavaScript,所以 Loader 就成了翻译官,对其他类型的资源进行转译的预处理工作loader在 module.rules 中配置,作为模块的解析规则,类型为数组。每一项都是一个 Object,内部包含了 test(类型文件)、loader、options(参数)等属性
- Plugin 可以用于执行更加广泛的任务,比如打包优化、资源管理、环境变量注入等
plugin就是插件,基于事件流框架 Tapable,插件可以扩展 Webpack 的功能,在 Webpack 运行的生命周期中会广播出许多事件,plugin 可以监听这些事件,在合适的时机通过 Webpack 提供的 API 改变输出结果plugin在 plugins 中单独配置,类型为数组,每一项是一个 plugin 的实例,参数都通过构造函数传入
- Loader 是用于特定的模块类型进行转换
mode 模式配置
Mode 配置选项,可以告知 webpack 使用相应模式的内置优化
- 默认值是 production(什么都不设置的情况下)
- 可选值有:‘none’ | ‘development’ | ‘production’
这几个选项有什么样的区别呢?
选项 描述 development会将 DefinePlugin中process.env.NODE_ENV的值设置为development. 为模块和 chunk 启用有效的名production会将 DefinePlugin中process.env.NODE_ENV的值设置为production。为模块和 chunk 启用确定性的混淆名称,FlagDependencyUsagePlugin,FlagIncludedChunksPlugin,ModuleConcatenationPlugin,NoEmitOnErrorsPlugin和TerserPluginnone不使用任何默认优化选项 Mode 配置代表更多

webpack 的模块化
- Webpack 打包的代码,允许我们使用各种各样的模块化,但是最常用的是CommonJS、ES Module
- 那么它是如何帮助我们实现了代码中支持模块化呢?
- 我们来研究一下它的原理,包括如下原理
- CommonJS 模块化实现原理
- ES Module 实现原理
- CommonJS 加载 ES Module 的原理
- ES Module 加载 CommonJS 的原理
认识 source-map
- 我们的代码通常运行在浏览器上时,是通过打包压缩的
- 也就是真实跑在浏览器上的代码,和我们编写的代码其实是有差异的
- 比如ES6 的代码可能被转换成ES5
- 比如对应的代码行号、列号在经过编译后肯定会不一致
- 比如代码进行丑化压缩时,会将编码名称等修改
- 比如我们使用了TypeScript等方式编写的代码,最终转换成JavaScript
- 但是,当代码报错需要调试时(debug),调试转换后的代码是很困难的
- 但是我们能保证代码不出错吗?不可能
- 那么如何可以调试这种转换后不一致的代码呢?答案就是source-map
- source-map 是从已转换的代码,映射到原始的源文件
- 使浏览器可以重构原始源并在调试器中显示重建的原始源
- source-map 是将编译、打包、压缩后的代码映射回源代码的过程。打包压缩后的代码不具备良好的可读性,想要调试源码就需要 soucre map
如何使用
如何可以使用 source-map 呢?两个步骤
- 第一步:根据源文件,生成 source-map 文件,webpack 在打包时,可以通过配置生成 source-map
- 第二步:在转换后的代码,最后添加一个注释,它指向 sourcemap
1
//# sourceMappingURL=common.bundle.js.map
浏览器会根据我们的注释,查找相应的 source-map,并且根据 source-map 还原我们的代码,方便进行调试
在 Chrome 中,我们可以按照如下的方式打开 source-map
- F12 —> 设置按钮 —> 源代码 —> 启用 JavaScript 源代码映射,启用 CSS 源代码映射
生成映射文件
- 如何在使用 webpack 打包的时候,生成对应的 source-map 呢?
- webpack 为我们提供了非常多的选项(目前是26 个),来处理 source-map
- https://webpack.docschina.org/configuration/devtool
- 选择不同的值,生成的 source-map 会稍微有差异,打包的过程也会有性能的差异,可以根据不同的情况进行选择
- 下面几个值不会生成 source-map
- false:不使用 source-map,也就是没有任何和 source-map 相关的内容
- none:production 模式下的默认值(什么值都不写) ,不生成 source-map
- eval:development 模式下的默认值,不生成 source-map
- 但是它会在 eval 执行的代码中,添加 //# sourceURL=
- 它会被浏览器在执行时解析,并且在调试面板中生成对应的一些文件目录,方便我们调试代码
分析映射文件
- 最初 source-map 生成的文件大小是原始文件的 10 倍,第二版减少了约 50%,第三版又减少了 50%,所以目前一个 133kb 的文件,最终的 source-map 的大小大概在 300kb
- 目前的 source-map 长什么样子呢?
- version:当前使用的版本,也就是最新的第三版
- sources:从哪些文件转换过来的 source-map 和打包的代码(最初始的文件)
- names:转换前的变量和属性名称(因为我目前使用的是 development 模式,所以不需要保留转换前的名称)
- mappings:source-map 用来和源文件映射的信息(比如位置信息等),一串 base64 VLQ(veriable-length quantity 可变长度值)编码
- file:打包后的文件(浏览器加载的文件)
- sourceContent:转换前的具体代码信息(和 sources 是对应的关系)
- sourceRoot:所有的 sources 相对的根目录
source-map
生成一个独立的 source-map 文件,并且在 bundle 文件中有一个注释,指向 source-map 文件
bundle 文件中有如下的注释
- 开发工具会根据这个注释找到 source-map 文件,并且解析
1
//# sourceMappingURL=bundle.js.map
eval-source-map
- 会生成 sourcemap,但是 source-map 是以DataUrl 添加到 eval 函数的后面
inline-source-map
- 会生成 sourcemap,但是 source-map 是以DataUrl添加到 bundle 文件的后面
cheap-source-map
- 会生成 sourcemap,但是会更加高效一些(cheap 低开销),因为它没有生成列映射(Column Mapping)
- 因为在开发中,我们只需要行信息通常就可以定位到错误了
cheap-module-source-map
- 会生成 sourcemap,类似于 cheap-source-map,但是对源自 loader 的 sourcemap 处理会更好
- 这里有一个很模糊的概念:对源自 loader 的 sourcemap 处理会更好,官方也没有给出很好的解释
- 其实是如果 loader 对我们的源码进行了特殊的处理
hidden-source-map
会生成 sourcemap,但是不会对 source-map 文件进行引用
相当于删除了打包文件中对 sourcemap 的引用注释
1
2// 被删除掉的
//# sourceMappingURL=bundle.js.map如果我们手动添加进来,那么 sourcemap 就会生效了
nosources-source-map
- 会生成 sourcemap,但是生成的 sourcemap只有错误信息的提示,不会生成源代码文件
- 正确的错误提示
- 点击错误提示,无法查看源码
多个值的组合
事实上,webpack 提供给我们的26 个值,是可以进行多组合的
组合的规则如下
- inline- | hidden- | eval:三选一
- nosources:可选值
- cheap 可选值,并且可以跟随 module 的值
1
[inline- | hidden- | eval-] [nosources-] [cheap- [module-] ] source-map
那么在开发中,最佳的实践是什么呢?
- 开发阶段:推荐使用 source-map 或者cheap-module-source-map
- 这分别是 vue 和 react 使用的值,可以获取调试信息,方便快速开发
- 测试阶段:推荐使用 source-map 或者cheap-module-source-map
- 测试阶段我们也希望在浏览器下看到正确的错误提示
- 发布阶段:false、缺省值(不写)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26const path = require("path");
module.exports = {
mode: "production",
// 常见的值:
// 1.false
// 2.none => production
// 3.eval => development
// 4.source-map => production
// 不常见的值:
// 1.eval-source-map: 添加到eval函数的后面
// 2.inline-source-map: 添加到文件的后面
// 3.cheap-source-map(dev环境): 低开销, 更加高效
// 4.cheap-module-source-map: 和cheap-source-map比较相似, 但是对来自loader的source-map处理的更好
// 5.hidden-source-map: 会生成sourcemap文件, 但是不会对source-map文件进行引用
devtool: "nosources-source-map",
entry: "./src/main.js",
output: {
path: path.resolve(__dirname, "./build"),
filename: "bundle.js",
},
module: {
rules: [{ test: /\.js$/, use: "babel-loader" }],
},
};- 开发阶段:推荐使用 source-map 或者cheap-module-source-map
开发服务器配置
为什么要搭建本地服务器?
- 目前我们开发的代码,为了运行需要有两个操作
- 操作一:npm run build,编译相关的代码
- 操作二:通过 live server 或者直接通过浏览器,打开 index.html 代码,查看效果
- 这个过程经常操作会影响我们的开发效率,我们希望可以做到,当文件发生变化时,可以自动的完成 编译 和 展示
- 为了完成自动编译,webpack 提供了几种可选的方式
- webpack watch mode
- webpack-dev-server(常用)
- webpack-dev-middleware
webpack-dev-server
上面的方式可以监听到文件的变化,但是事实上它本身是没有自动刷新浏览器的功能的
- 当然,目前我们可以在 VSCode 中使用 live-server 来完成这样的功能
- 但是,我们希望在不适用 live-server 的情况下,可以具备 live reloading(实时重新加载)的功能
安装 webpack-dev-server
1
npm install webpack-dev-server -D
修改配置文件,启动时加上 serve 参数
1
"serve": "webpack serve"
webpack-dev-server 在编译之后不会写入到任何输出文件,而是将 bundle 文件保留在内存中
- 事实上 webpack-dev-server 使用了一个库叫 memfs(memory-fs webpack 自己写的)
认识模块热替换(HMR)
- 什么是 HMR 呢?
- HMR 的全称是Hot Module Replacement,翻译为模块热替换
- 模块热替换是指在 应用程序运行过程中,替换、添加、删除模块,而无需重新刷新整个页面
- HMR 通过如下几种方式,来提高开发的速度
- 不重新加载整个页面,这样可以保留某些应用程序的状态不丢失
- 只更新需要变化的内容,节省开发的时间
- 修改了 css、js 源代码,会立即在浏览器更新,相当于直接在浏览器的 devtools 中直接修改样式
- 如何使用 HMR 呢?
- 默认情况下,webpack-dev-server 已经支持 HMR,我们只需要开启即可(默认已经开启)
- 在不开启 HMR 的情况下,当我们修改了源代码之后,整个页面会自动刷新,使用的是 live reloading
devServer 的 static
devServer 中 static 对于我们直接访问打包后的资源其实并没有太大的作用,它的主要作用是如果我们打包后的资源,又依赖于其他的一些资源,那么就需要指定从哪里来查找这个内容
- 比如在 index.html 中,我们需要依赖一个 abc.js 文件,这个文件我们存放在 public 文件 中
- 在 index.html 中,我们应该如何去引入这个文件呢?
- 比如代码是这样的:
<script src="./public/abc.js"></script> - 但是这样打包后浏览器是无法通过相对路径去找到这个文件夹的
- 所以代码是这样的:
<script src="/abc.js"></script> - 但是我们如何让它去查找到这个文件的存在呢? 设置 static 即可
- 比如代码是这样的:
1
2
3devServer: {
static: ['public', 'content'],
}
hotOnly、host 配置
- hotOnly 是当代码编译失败时,是否刷新整个页面
- 默认情况下当代码编译失败修复后,我们会重新刷新整个页面
- 如果不希望重新刷新整个页面,可以设置 hotOnly 为 true
- host 设置主机地址
- 默认值是 localhost
- 如果希望其他地方也可以访问,可以设置为 0.0.0.0
- localhost 和 0.0.0.0 的区别
- localhost:本质上是一个域名,通常情况下会被解析成 127.0.0.1
- 127.0.0.1:回环地址(Loop Back Address),表达的意思其实是我们主机自己发出去的包,直接被自己接收
- 正常的数据库包经常 应用层 - 传输层 - 网络层 - 数据链路层 - 物理层
- 而回环地址,是在网络层直接就被获取到了,是不会经常数据链路层和物理层的
- 比如我们监听 127.0.0.1 时,在同一个网段下的主机中,通过 ip 地址是不能访问的
- 0.0.0.0:监听 IPV4 上所有的地址,再根据端口找到不同的应用程序
- 比如我们监听 0.0.0.0 时,在同一个网段下的主机中,通过 ip 地址是可以访问的
port、open、compress
- port 设置监听的端口,默认情况下是 8080
- open 是否打开浏览器
- 默认值是 false,设置为 true 会打开浏览器
- 也可以设置为类似于 Google Chrome 等值
- compress 是否为静态文件开启 gzip compression
- 默认值是 false,可以设置为 true
Proxy 代理
proxy 是我们开发中非常常用的一个配置选项,它的目的设置代理来解决跨域访问的问题
- 比如我们的一个 api 请求是 http://localhost:8888 ,但是本地启动的服务器域名是 http://localhost:8080 ,这个时候发送网络请求就会出现跨域的问题
- 那么我们可以将请求先发送到一个代理服务器,代理服务器和 API 服务器没有跨域的问题,就可以解决我们的跨域问题了
我们可以进行如下的设置
- target:表示的是代理到的目标地址,比如 axios.get(“/api/moment”) 会被代理到 http://localhost:8888/api/moment
- pathRewrite:默认情况下,我们的 /api 也会被写入到 URL 中,如果希望删除,可以使用 pathRewrite
- changeOrigin:它表示是否更新代理后请求的 headers 中 host 地址
1
2
3
4
5
6
7
8
9
10
11
12devServer: {
proxy: {
'/api': {
target: 'http://localhost:8888',
pathRewrite: {
'^/api': ''
},
changeOrigin: true
}
}
}
changeOrigin 的解析
这个 changeOrigin 官方说的非常模糊,通过查看源码我发现其实是要修改代理请求中的 headers 中的 host 属性
- 因为我们真实的请求,其实是需要通过 http://localhost:8888 来请求的
- 但是因为使用了代理,默认情况下它的值时 http://localhost:8080
- 如果我们需要修改,那么可以将 changeOrigin 设置为 true 即可
1
2
3
4
5
6
7
8// node_modules\http-proxy\lib\http-proxy\common.js ---> setupOutgoing
if (options.changeOrigin) {
outgoing.headers.host =
required(outgoing.port, options[forward || "target"].protocol) &&
!hasPort(outgoing.host)
? outgoing.host + ":" + outgoing.port
: outgoing.host;
}
historyApiFallback
historyApiFallback 是开发中一个非常常见的属性,它主要的作用是解决 SPA 页面在路由跳转之后,进行页面刷新时,返回 404 的错误
boolean 值:默认是 false
- 如果设置为 true,那么在刷新时,返回 404 错误时,会自动返回 index.html 的内容
object 类型的值,可以配置 rewrites 属性
- 可以配置 from 来匹配路径,决定要跳转到哪一个页面
事实上 devServer 中实现 historyApiFallback 功能是通过 connect-history-api-fallback 库的
- 可以查看 connect-history-api-fallback 文档
区分开发和生成环境配置
目前我们所有的 webpack 配置信息都是放到一个配置文件中的:webpack.config.js
- 当配置越来越多时,这个文件会变得越来越不容易维护
- 并且某些配置是在开发环境需要使用的,某些配置是在生成环境需要使用的,当然某些配置是在开发和生成环境都会使用的
- 所以,我们最好对配置进行划分,方便我们维护和管理
那么,在启动时如何可以区分不同的配置呢?
- 方案一:编写两个不同的配置文件,开发和生成时,分别加载不同的配置文件即可
- 方式二:使用相同的一个入口配置文件,通过设置参数来区分它们
1
2
3
4"scripts": {
"build": "webpack --config ./config/common.conf.js --env production",
"serve": "webpack serve --config ./config/common.conf.js --env development",
},这里我们创建三个文件
- common.conf.js
- dev.config.js
- prod.config.js
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46const path = require("path");
const HtmlWebpackPlugin = require("html-webpack-plugin");
const MiniCssExtractPlugin = require("mini-css-extract-plugin");
const { merge } = require("webpack-merge");
const devConfig = require("./dev.config");
const prodConfig = require("./prod.config");
/**
* 抽取开发和生产环境的配置文件
* 1.将配置文件导出的是一个函数, 而不是一个对象
* 2.从上向下查看所有的配置属性应该属于哪一个文件
* * common/dev/prod
* 3.针对单独的配置文件进行定义化
* * css加载: 使用的不同的loader可以根据isProduction动态获取
*/
const getCommonConfig = function (isProduction) {
let cssLoader = isProduction ? MiniCssExtractPlugin.loader : "style-loader";
return {
entry: "./src/main.js",
output: {
clean: true,
path: path.resolve(__dirname, "../build"),
filename: "js/[name]-bundle.js",
chunkFilename: "js/[name]_chunk.js",
},
resolve: {
extensions: [".js", ".json", ".wasm", ".jsx", ".ts"],
},
module: {
rules: [
{ test: /\.js$/, use: { loader: "babel-loader" } },
{ test: /\.ts$/, use: "babel-loader" },
{ test: /\.css$/, use: [cssLoader, "css-loader"] },
],
},
plugins: [new HtmlWebpackPlugin({ template: "./index.html" })],
};
};
// webpack 允许导出一个函数
module.exports = function (env) {
const isProduction = env.production;
let mergeConfig = isProduction ? prodConfig : devConfig;
return merge(getCommonConfig(isProduction), mergeConfig);
};1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// dev.config.js
module.exports = {
mode: "development",
devServer: {
static: ["public", "content"],
port: 3000,
compress: true,
proxy: {
"/api": {
target: "http://localhost:9000",
pathRewrite: { "^/api": "" },
changeOrigin: true,
},
},
historyApiFallback: true,
},
};1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41// prod.config.js
const TerserPlugin = require("terser-webpack-plugin");
const MiniCssExtractPlugin = require("mini-css-extract-plugin");
const CSSMinimizerPlugin = require("css-minimizer-webpack-plugin");
module.exports = {
mode: "production",
optimization: {
chunkIds: "deterministic",
runtimeChunk: { name: "runtime" },
splitChunks: {
chunks: "all",
minSize: 10,
cacheGroups: {
utils: { test: /utils/, filename: "js/[id]_utils.js" },
vendors: {
test: /[\\/]node_modules[\\/]/,
filename: "js/[id]_vendors.js",
},
},
},
minimize: true,
minimizer: [
new TerserPlugin({
extractComments: false,
terserOptions: {
compress: { arguments: true, unused: true },
mangle: true,
keep_fnames: true,
},
}),
new CSSMinimizerPlugin({}),
],
},
plugins: [
new MiniCssExtractPlugin({
filename: "css/[name].css",
chunkFilename: "css/[name]_chunk.css",
}),
],
};
入口文件解析
我们之前编写入口文件的规则是这样的:./src/index.js,但是如果我们的配置文件所在的位置变成了 config 目录,我们是否应该变成 …/src/index.js 呢?
- 如果我们这样编写,会发现是报错的,依然要写成 ./src/index.js
- 这是因为入口文件其实是和另一个属性时有关的 context
context 的作用是用于解析入口(entry point)和加载器(loader)
- 官方说法:默认是当前路径(但是经过我测试,默认应该是 webpack 的启动目录)
- 另外推荐在配置中传入一个值
1
2
3
4
5
6
7
8
9
10
11// context 是配置文件所在目录
module.exports = {
context: path.resolve(__dirname, "./"),
entry: "../src/index.js",
};
// context 是上一个目录
module.exports = {
context: path.resolve(__dirname, "../"),
entry: "./src/index.js",
};
性能优化方案
如何使用 webpack 性能优化?
- webpack 作为前端目前使用最广泛的打包工具,在面试中也是经常会被问到的
- 比较常见的面试题包括
- 可以配置哪些属性来进行webpack 性能优化?
- 前端有哪些常见的性能优化?(问到前端性能优化时,除了其他常见的,也完全可以从 webpack 来回答)
- webpack 的性能优化较多,我们可以对其进行分类
- 优化一:打包后的结果,上线时的性能优化。(比如分包处理、减小包体积、CDN 服务器等)
- 优化二:优化打包速度,开发或者构建时优化打包速度。(比如 exclude、cache-loader 等)
- 大多数情况下,我们会更加侧重于优化一,这对于线上的产品影响更大
- 在大多数情况下 webpack 都帮我们做好了该有的性能优化
- 比如配置 mode 为 production 或者 development 时,默认 webpack 的配置信息
- 但是我们也可以针对性的进行自己的项目优化
代码分离
- 代码分离(Code Splitting)是 webpack 一个非常重要的特性
- 它主要的目的是将代码分离到不同的 bundle 中,之后我们可以按需加载,或者并行加载这些文件
- 比如默认情况下,所有的 JavaScript 代码(业务代码、第三方依赖、暂时没有用到的模块)在首页全部都加载,就会影响首页的加载速度
- 代码分离可以分出更小的 bundle,以及控制资源加载优先级,提供代码的加载性能
- Webpack 中常用的代码分离有三种
- 入口起点:使用 entry 配置手动分离代码
- 防止重复:使用 Entry Dependencies 或者 SplitChunksPlugin 去重和分离代码
- 动态导入:通过模块的内联函数调用来分离代码
多入口起点
入口起点的含义非常简单,就是配置多入口
- 比如配置一个 index.js 和 main.js 的入口
- 他们分别有自己的代码逻辑
1
2
3
4
5
6
7
8entry: {
index: "./src/index.js",
main: "./src/main.js",
},
output: {
filename: "[name]-bundle.js",
path: path.resolve(__dirname, "./build"),
},
Entry Dependencies
假如我们的 index.js 和 main.js 都依赖两个库:lodash、dayjs
- 如果我们单纯的进行入口分离,那么打包后的两个 bunlde 都有会有一份 lodash 和 dayjs
- 事实上我们可以对他们进行共享
1
2
3
4
5entry: {
index: { import: "./src/index.js", dependOn: "shared1" },
main: { import: "./src/main.js", dependOn: "shared1" },
shared1: ["lodash", "dayjs"],
},
SplitChunks
另外一种分包的模式是splitChunk,它底层是使用SplitChunksPlugin来实现的
- 因为该插件 webpack 已经默认安装和集成,所以我们并不需要单独安装和直接使用该插件
- 只需要提供 SplitChunksPlugin 相关的配置信息即可
Webpack 提供了 SplitChunksPlugin 默认的配置,我们也可以手动来修改它的配置
- 比如默认配置中,chunks 仅仅针对于异步(async)请求,我们可以设置为 initial 或者 all
1
2
3
4optimization: {
splitChunks: {
chunks: "all",
},
SplitChunks 自定义配置解析
chunks
- 默认值是 async
- 另一个值是 initial,表示对通过的代码进行处理
- all 表示对同步和异步代码都进行处理
minSize
- 拆分包的大小, 至少为 minSize
- 如果一个包拆分出来达不到 minSize,那么这个包就不会拆分
maxSize
- 将大于 maxSize 的包,拆分为不小于 minSize 的包
cacheGroups
- 用于对拆分的包就行分组,比如一个 lodash 在拆分之后,并不会立即打包,而是会等到有没有其他符合规则的包一起来打包
- test 属性:匹配符合规则的包
- name 属性:拆分包的 name 属性
- filename 属性:拆分包的名称,可以自己使用 placeholder 属性
当然,我们可以自定义更多配置,我们来了解几个非常关键的属性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45const TerserPlugin = require("terser-webpack-plugin");
// 优化配置
optimization: {
// 设置生成的chunkId的算法
// development: named
// production: deterministic(确定性)
// webpack4中使用: natural
chunkIds: "deterministic",
// runtime的代码是否抽取到单独的包中(早Vue2脚手架中)
runtimeChunk: {
name: "runtime",
},
// 分包插件: SplitChunksPlugin
splitChunks: {
chunks: "all",
// 当一个包大于指定的大小时, 继续进行拆包
// maxSize: 20000,
// 将包拆分成不小于minSize的包
// minSize: 10000,
minSize: 10,
// 自己对需要进行拆包的内容进行分包
cacheGroups: {
utils: { test: /utils/, filename: "js/[id]_utils.js" },
vendors: {
// /node_modules/
// window上面 / or \
// mac上面 /
test: /[\\/]node_modules[\\/]/,
filename: "js/[id]_vendors.js",
},
},
},
minimize: true,
// 代码优化: TerserPlugin => 让代码更加简单 => Terser
minimizer: [
// JS代码简化
new TerserPlugin({
// 默认情况下,webpack 在进行分包时,有对包中的注释进行单独提取
// 这个包提取是由另一个插件默认配置的原因
extractComments: false,
}),
],
},
chunkIds
- optimization.chunkIds 配置用于告知 webpack 模块的 id 采用什么算法生成
- 有三个比较常见的值
- natural:按照数字的顺序使用 id
- named:development 下的默认值,一个可读的名称的 id
- deterministic:确定性的,在不同的编译中不变的短数字 id
- 在 webpack4 中是没有这个值的
- 那个时候如果使用 natural,那么在一些编译发生变化时,就会有问题
- 最佳实践
- 开发过程中,我们推荐使用 named
- 打包过程中,我们推荐使用 deterministic
runtimeChunk
- 配置 runtime 相关的代码是否抽取到一个单独的 chunk 中
- runtime 相关的代码指的是在运行环境中,对模块进行解析、加载、模块信息相关的代码
- 比如我们的 component、bar 两个通过 import 函数相关的代码加载,就是通过 runtime 代码完成的
- 抽离出来后,有利于浏览器缓存的策略
- 比如我们修改了业务代码(main),那么runtime 和 component、bar 的 chunk 是不需要重新加载的
- 比如我们修改了 component、bar 的代码,那么main 中的代码是不需要重新加载的
- 设置的值
- true/multiple:针对每个入口打包一个 runtime 文件
- single:打包一个 runtime 文件
- 对象:name 属性决定 runtimeChunk 的名称
动态导入
- 另外一个代码拆分的方式是动态导入时,webpack 提供了两种实现动态导入的方式
- 第一种,使用 ECMAScript 中的 import() 语法来完成,也是目前推荐的方式
- 第二种,使用 webpack 遗留的 require.ensure,目前已经不推荐使用
- 比如我们有一个模块 bar.js
- 该模块我们希望在代码运行过程中来加载它(比如判断一个条件成立时加载)
- 因为我们并不确定这个模块中的代码一定会用到,所以最好拆分成一个独立的 js 文件
- 这样可以保证不用到该内容时,浏览器不需要加载和处理该文件的 js 代码
- 这个时候我们就可以使用动态导入
- 注意:使用动态导入 bar.js
- 在 webpack 中,通过动态导入获取到一个对象
- 真正导出的内容,在该对象的 default 属性中,所以我们需要做一个简单的解构
动态导入的文件命名
动态导入的文件命名
- 因为动态导入通常是一定会打包成独立的文件的,所以并不会再 cacheGroups 中进行配置
- 那么它的命名我们通常会在 output 中,通过 chunkFilename 属性来命名
1
2
3
4
5
6
7
8entry: "./src/main.js",
output: {
path: path.resolve(__dirname, "./build"),
filename: "[name]-bundle.js",
// 单独针对分包的文件进行命名
chunkFilename: "[id]_[name]_chunk.js",
clean: true,
},但是,你会发现默认情况下我们获取到的 [name] 是和 id 的名称保持一致的
- 如果我们希望修改 name 的值,可以通过 magic comments(魔法注释)的方式
1
2
3import(/* webpackChunkName: "bar" */ "./bar.js").then((res) => {
res.bar();
});
代码的懒加载
动态 import 使用最多的一个场景是懒加载(比如路由懒加载)
- 封装一个 component.js,返回一个 component 对象
- 我们可以在一个按钮点击时,加载这个对象
1
2
3
4const element = document.createElement("div");
element.textContent = "Hello Component";
export default element;1
2
3
4
5
6
7
8
9const btn = document.createElement("button");
btn.textContent = "获取组件";
btn.onclick = function () {
import(/* webpackChunkName: "component" */ "./component.js").then((res) => {
document.body.append(res.default);
});
};
document.body.append(btn);
Prefetch 和 Preload
webpack v4.6.0+ 增加了对预获取和预加载的支持
在声明 import 时,使用下面这些内置指令,来告知浏览器
- prefetch(预获取):将来某些导航下可能需要的资源
- preload(预加载):当前导航下可能需要资源
1
2
3
4
5
6
7import(
/* webpackChunkName: "component" */
/* webpackPrefetch: true */
"./component.js"
).then((res) => {
document.body.append(res.default);
});与 prefetch 指令相比,preload 指令有许多不同之处
- preload chunk 会在父 chunk 加载时,以并行方式开始加载。prefetch chunk 会在父 chunk 加载结束后开始加载
- preload chunk 具有中等优先级,并立即下载。prefetch chunk 在浏览器闲置时下载
- preload chunk 会在父 chunk 中立即请求,用于当下时刻。prefetch chunk 会用于未来的某个时刻
什么是 CDN?
- CDN 称之为内容分发网络(Content Delivery Network 或 Content Distribution Network,缩写:CDN)
- 它是⼀组分布在不同地理位置的服务器相互连接形成的网络系统,通过这个网络系统,将资源存放在距离用户最近的服务器
- 可以更快、更可靠地将资源(文件、图片、音乐、视频等)发送给用户
- 来提供高性能、可扩展性及低成本的网络内容传递给用户
- CDN 有什么作用?
- CDN 会将资源缓存到遍布全球的网站,用户获取资源时,可就近获取 CDN 上缓存的资源
- 这样 CDN 不但可以提高资源的访问速度,还可以分担源站的压力
- 在开发中,我们使用 CDN 主要是两种方式
- 方式一:打包的所有静态资源,放到 CDN 服务器,用户所有资源都是通过 CDN 服务器加载的
- 方式二:一些第三方资源放到 CDN 服务器上
购买 CDN 服务器
如果所有的静态资源都想要放到 CDN 服务器上,我们需要购买自己的 CDN 服务器
- 目前阿里、腾讯、亚马逊、Google 等都可以购买 CDN 服务器
- 我们可以直接修改 publicPath,在打包时添加上自己的 CDN 地址
1
2
3output: {
publicPath: 'https://xxx.com/cdn/'
},1
2<script src="https://xxx.com/cdn/axios.min.js"></script>
<script src="https://xxx.com/cdn/react.min.js"></script>
第三方库的 CDN 服务器
通常一些比较出名的开源框架都会将打包后的源码放到一些比较出名的、免费的 CDN 服务器上
- 国际上使用比较多的是 unpkg、JSDelivr、cdnjs
- 国内也有一个比较好用的 CDN 是 bootcdn
在项目中,我们如何去引入这些 CDN 呢?
- 第一,在打包的时候我们不再需要对类似于 lodash 或者 dayjs 这些库进行打包
- 第二,在 html 模块中,我们需要自己加入对应的 CDN 服务器地址
第一步,我们可以通过 webpack 配置,来排除一些库的打包
第二步,在 html 模块中,加入 CDN 服务器地址
1
2
3
4
5
6
7// 排除某些包不需要进行打包
externals: {
lodash: "_",
// key: 排除的框架的名称 import xxx from "lodash" <--- key ("lodash")
// value: 从CDN地址请求下来的js中提供的全局变量
dayjs: "dayjs"
},1
2<script src="https://cdn.bootcdn.net/ajax/libs/lodash.js/4.17.21/lodash.min.js"></script>
<script src="https://cdn.bootcdn.net/ajax/libs/dayjs/1.11.7/dayjs.min.js"></script>
认识 shimming
- shimming 是一个概念,是某一类功能的统称
- shimming 翻译过来我们称之为 垫片,相当于给我们的代码填充一些垫片来处理一些问题
- 比如我们现在依赖一个第三方的库,这个第三方的库本身依赖 lodash,但是默认没有对 lodash 进行导入(认为全局存在 lodash),那么我们就可以通过 ProvidePlugin 来实现 shimming 的效果
- 注意:webpack 并不推荐随意的使用 shimming
- Webpack 背后的整个理念是使前端开发更加模块化
- 也就是说,需要编写具有封闭性的、不存在隐含依赖(比如全局变量)的彼此隔离的模块
预支全局变量
目前我们的 lodash、dayjs 都使用了 CDN 进行引入,所以相当于在全局是可以使用_和 dayjs 的
- 假如一个文件中我们使用了 axios,但是没有对它进行引入,那么下面的代码是会报错的
1
2
3
4
5
6
7axios.get("http://123.207.32.32:8000/home/multidata").then((res) => {
console.log(res);
});
get("http://123.207.32.32:8000/home/multidata").then((res) => {
console.log(res);
});我们可以通过使用 ProvidePlugin 来实现 shimming 的效果
- ProvidePlugin能够帮助我们在每个模块中,通过一个变量来获取一个 package
- 如果 webpack 看到这个模块,它将在最终的 bundle 中引入这个模块
- 另外 ProvidePlugin 是webpack 默认的一个插件,所以不需要专门导入
1
2
3
4
5
6
7
8const { ProvidePlugin } = require("webpack");
plugins: [
new ProvidePlugin({
axios: ["axios", "default"],
get: ["axios", "default", "get"],
}),
];这段代码的本质是告诉 webpack
- 如果你遇到了至少一处用到 axios 变量的模块实例,那请你将 axios package 引入进来,并将其提供给需要用到它的模块
MiniCssExtractPlugin
MiniCssExtractPlugin 可以帮助我们将 css 提取到一个独立的 css 文件中,该插件需要在 webpack4+才可以使用
首先,我们需要安装 mini-css-extract-plugin
1
npm install mini-css-extract-plugin -D
配置 rules 和 plugins
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16const MiniCssExtractPlugin = require('mini-css-extract-plugin')
module: {
rules: [
// 'style-loader', 开发阶段
// MiniCssExtractPlugin.loader, // 生产阶段
{test: /\.css$/, use: [MiniCssExtractPlugin.loader, 'css-loader']}
]
},
plugins: [
new MiniCssExtractPlugin({
filename: 'css/[name].css',
chunkFilename: 'css/[name]_chunk.css'
})
]
Hash、ContentHash、ChunkHash
- 在我们给打包的文件进行命名的时候,会使用 placeholder,placeholder 中有几个属性比较相似
- hash、chunkhash、contenthash
- hash 本身是通过 MD4 的散列函数处理后,生成一个 128 位的 hash 值(32 个十六进制)
- hash 值的生成和整个项目有关系
- 比如我们现在有两个入口 index.js 和 main.js
- 它们分别会输出到不同的 bundle 文件中,并且在文件名称中我们有使用 hash
- 这个时候,如果修改了 index.js 文件中的内容,那么 hash 会发生变化
- 那就意味着两个文件的名称都会发生变化
- chunkhash 可以有效的解决上面的问题,它会根据不同的入口进行解析来生成 hash 值
- 比如我们修改了 index.js,那么 main.js 的 chunkhash 是不会发生改变的
- contenthash 表示生成的文件 hash 名称,只和内容有关系
- 比如我们的 index.js,引入了一个 style.css,style.css 有被抽取到一个独立的 css 文件中
- 这个 css 文件在命名时,如果我们使用的是 chunkhash
- 那么当 index.js 文件的内容发生变化时,css 文件的命名也会发生变化
- 这个时候我们可以使用 contenthash
认识 DLL 库
- DLL 是什么呢?
- DLL 全程是动态链接库(Dynamic Link Library),是为软件在 Windows 中实现共享函数库的一种实现方式
- 那么 webpack 中也有内置 DLL 的功能,它指的是我们可以将能够共享,并且不经常改变的代码,抽取成一个共享的库
- 这个库在之后编译的过程中,会被引入到其他项目的代码中
- DDL 库的使用分为两步
- 第一步:打包一个 DLL 库
- 第二步:项目中引入 DLL 库
认识 Terser
什么是 Terser 呢?
- Terser 是一个 JavaScript 的解释(Parser)、Mangler(绞肉机)/Compressor(压缩机)的工具集
- 早期我们会使用 uglify-js 来压缩、丑化我们的 JavaScript 代码,但是目前已经不再维护,并且不支持 ES6+的语法
- Terser 是从 uglify-es fork 过来的,并且保留它原来的大部分 API 以及适配 uglify-es 和 uglify-js@3 等
也就是说,Terser 可以帮助我们压缩、丑化我们的代码,让我们的 bundle 变得更小
因为 Terser 是一个独立的工具,所以它可以单独安装
1
2
3
4# 全局安装
npm install terser -g
# 局部安装
npm install terser -D
命令行使用
我们可以在命令行中使用 Terser
1
2
3terser [input files] [options]
# 举例说明
terser js/file1.js -o foo.min.js -c -m我们这里来讲解几个 Compress option 和 Mangle(乱砍) option
- 因为他们的配置非常多,我们不可能一个个解析,更多的查看文档即可
- https://github.com/terser/terser#compress-options
- https://github.com/terser/terser#mangle-options
Compress 和 Mangle 的 options
Compress option
- arrows:class 或者 object 中的函数,转换成箭头函数
- arguments:将函数中使用 arguments[index]转成对应的形参名称
- dead_code:移除不可达的代码(tree shaking)
- 其他属性可以查看文档
Mangle option
- toplevel:默认值是 false,顶层作用域中的变量名称,进行丑化(转换)
- keep_classnames:默认值是 false,是否保持依赖的类名称
- keep_fnames:默认值是 false,是否保持原来的函数名称
- 其他属性可以查看文档
1
2npx terser ./src/abc.js -o abc.min.js -c arrows,arguments=true,dead_code -m
toplevel=true,keep_classnames=true,keep_fnames=true
Terser 在 webpack 中配置
真实开发中,我们不需要手动的通过 terser 来处理我们的代码,我们可以直接通过 webpack 来处理
- 在 webpack 中有一个 minimizer 属性,在 production 模式下,默认就是使用 TerserPlugin 来处理我们的代码的
- 如果我们对默认的配置不满意,也可以自己来创建 TerserPlugin 的实例,并且覆盖相关的配置
首先,我们需要打开 minimize,让其对我们的代码进行压缩(默认 production 模式下已经打开了)
其次,我们可以在 minimizer 创建一个 TerserPlugin
- extractComments:默认值为 true,表示会将注释抽取到一个单独的文件中
- 在开发中,我们不希望保留这个注释时,可以设置为 false
- parallel:使用多进程并发运行提高构建的速度,默认值是 true
- 并发运行的默认数量: os.cpus().length - 1
- 我们也可以设置自己的个数,但是使用默认值即可
- terserOptions:设置我们的 terser 相关的配置
- compress:设置压缩相关的选项
- mangle:设置丑化相关的选项,可以直接设置为 true
- toplevel:顶层变量是否进行转换
- keep_classnames:保留类的名称
- keep_fnames:保留函数的名称
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17optimization: {
minimize: true,
minimizer: [
new TerserPlugin({
extractComments: false,
terserOptions: {
compress: {
arguments: true,
unused: true,
},
mangle: true,
toplevel: true
keep_fnames: true,
},
}),
],
},- extractComments:默认值为 true,表示会将注释抽取到一个单独的文件中
CSS 的压缩
另一个代码的压缩是 CSS
- CSS 压缩通常是去除无用的空格等,因为很难去修改选择器、属性的名称、值等
- CSS 的压缩我们可以使用另外一个插件:css-minimizer-webpack-plugin
- css-minimizer-webpack-plugin 是使用 cssnano 工具来优化、压缩 CSS(也可以单独使用)
第一步,安装 css-minimizer-webpack-plugin
1
npm install css-minimizer-webpack-plugin -D
第二步,在 optimization.minimizer 中配置
1
2
3
4
5
6
7
8
9const CSSMinimizerPlugin = require("css-minimizer-webpack-plugin");
optimization: {
minimizer: [
new CSSMinimizerPlugin({
parallel: true,
}),
],
},
什么是 Tree Shaking
- 什么是 Tree Shaking 呢?
- Tree Shaking 是一个术语,在计算机中表示消除死代码(dead_code)
- 最早的想法起源于 LISP,用于消除未调用的代码(纯函数无副作用,可以放心的消除,这也是为什么要求我们在进行函数式编程时,尽量使用纯函数的原因之一)
- 后来 Tree Shaking 也被应用于其他的语言,比如JavaScript、Dart
- JavaScript 的 Tree Shaking
- 对 JavaScript 进行 Tree Shaking 是源自打包工具 rollup(后面我们也会讲的构建工具)
- 这是因为 Tree Shaking 依赖于 ES Module 的静态语法分析(不执行任何的代码,可以明确知道模块的依赖关系)
- webpack2 正式内置支持了 ES2015 模块,和检测未使用模块的能力
- 在 webpack4 正式扩展了这个能力,并且通过 package.json 的 sideEffects 属性作为标记,告知 webpack 在编译时,哪里文件可以安全的删除掉
- webpack5 中,也提供了对部分 CommonJS 的 tree shaking 的支持
webpack 实现 Tree Shaking
- 事实上 webpack 实现 Tree Shaking 采用了两种不同的方案
- usedExports:通过标记某些函数是否被使用,之后通过 Terser 来进行优化的
- sideEffects:跳过整个模块/文件,直接查看该文件是否有副作用
usedExports
将 mode 设置为 development 模式
- 为了可以看到 usedExports 带来的效果,我们需要设置为 development 模式
- 因为在 production 模式下,webpack 默认的一些优化会带来很大的影响
设置 usedExports 为 true 和 false 对比打包后的代码
- 在 usedExports 设置为 true 时,会有一段注释:unused harmony export mul
- 这段注释的意义是什么呢?告知 Terser 在优化时,可以删除掉这段代码
这个时候,我们讲 minimize 设置 true
- usedExports 设置为 false 时,mul 函数没有被移除掉
- usedExports 设置为 true 时,mul 函数有被移除掉
所以,usedExports 实现 Tree Shaking 是结合 Terser 来完成的
1
2
3optimization: {
usedExports: true,
},
sideEffects
sideEffects 用于告知 webpack compiler 哪些模块时有副作用的
- 副作用的意思是这里面的代码有执行一些特殊的任务,不能仅仅通过 export 来判断这段代码的意义
- 副作用的问题,在讲 React 的纯函数时是有讲过的
在 package.json 中设置 sideEffects 的值
- 如果我们将 sideEffects 设置为 false,就是告知 webpack 可以安全的删除未用到的 exports
- 如果有一些我们希望保留,可以设置为数组
比如我们有一个 format.js、style.css 文件
- 该文件在导入时没有使用任何的变量来接受
- 那么打包后的文件,不会保留 format.js、style.css 相关的任何代码
1
2
3
4"sideEffects": [
"./src/util/format.js",
"*.css"
],
webpack 中 tree shaking 的设置
- 所以,如何在项目中对 JavaScript 的代码进行 TreeShaking 呢(生产环境)?
- 在 optimization 中配置 usedExports 为 true,来帮助 Terser 进行优化
- 在 package.json 中配置 sideEffects,直接对模块进行优化
CSS 实现 Tree Shaking
上面我们学习的都是关于 JavaScript 的 Tree Shaking,那么 CSS 是否也可以进行 Tree Shaking 操作呢?
- CSS 的 Tree Shaking 需要借助于一些其他的插件
- 在早期的时候,我们会使用 PurifyCss 插件来完成 CSS 的 tree shaking,但是目前该库已经不再维护了(最新更新也是在 4 年前了)
- 目前我们可以使用另外一个库来完成 CSS 的 Tree Shaking:PurgeCSS,也是一个帮助我们删除未使用的 CSS 的工具
安装 PurgeCss 的 webpack 插件
1
npm install purgecss-webpack-plugin -D
配置 PurgeCss
配置这个插件(生成环境)
- paths:表示要检测哪些目录下的内容需要被分析,这里我们可以使用 glob
- 默认情况下,Purgecss 会将我们的 html 标签的样式移除掉,如果我们希望保留,可以添加一个 safelist 的属性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// npm install glob@7.*
const { PurgeCSSPlugin } = require('purgecss-webpack-plugin')
plugins: [
new PurgeCSSPlugin({
paths: glob.sync(`${path.resolve(__dirname, "../src")}/**/*`, {
nodir: true,
}),
safelist: function () {
return {
standard: ["body"],
};
},
}),
],purgecss 也可以对 less 文件进行处理(所以它是对打包后的 css 进行 tree shaking 操作)
Scope Hoisting
什么是 Scope Hoisting 呢?
- Scope Hoisting 从 webpack3 开始增加的一个新功能
- 功能是对作用域进行提升,并且让 webpack 打包后的代码更小、运行更快
默认情况下 webpack 打包会有很多的函数作用域,包括一些(比如最外层的)IIFE
- 无论是从最开始的代码运行,还是加载一个模块,都需要执行一系列的函数
- Scope Hoisting 可以将函数合并到一个模块中来运行
使用 Scope Hoisting 非常的简单,webpack 已经内置了对应的模块
- 在 production 模式下,默认这个模块就会启用
- 在 development 模式下,我们需要自己来打开该模块
1
plugins: [new webpack.optimize.ModuleConcatenationPlugin()];
什么是 HTTP 压缩?
- HTTP 压缩是一种内置在 服务器 和 客户端 之间的,以改进传输速度和带宽利用率的方式
- HTTP 压缩的流程什么呢?
- 第一步:HTTP 数据在服务器发送前就已经被压缩了;(可以在 webpack 中完成)
- 第二步:兼容的浏览器在向服务器发送请求时,会告知服务器自己支持哪些压缩格式
- Accept-Encoding: gzip,deflate
- 第三步:服务器在浏览器支持的压缩格式下,直接返回对应的压缩后的文件,并且在响应头中告知浏览器
- Content-Encoding: gzip
目前的压缩格式
- 目前的压缩格式非常的多
- compress – UNIX 的 “compress” 程序的方法(历史性原因,不推荐大多数应用使用,应该使用 gzip 或 deflate)
- deflate – 基于 deflate 算法(定义于 RFC 1951)的压缩,使用 zlib 数据格式封装
- gzip – GNU zip 格式(定义于 RFC 1952),是目前使用比较广泛的压缩算法
- br – 一种新的开源压缩算法,专为 HTTP 内容的编码而设计
webpack 对文件压缩
webpack 中相当于是实现了 HTTP 压缩的第一步操作,我们可以使用 CompressionPlugin
第一步,安装 CompressionPlugin
1
npm install compression-webpack-plugin -D
第二步,使用 CompressionPlugin 即可
1
2
3
4
5
6
7
8
9const CompressionPlugin = require("compression-webpack-plugin");
plugins: [
// 对打包后的文件(js/css)进行压缩
new CompressionPlugin({
test: /\.(js|css)$/,
algorithm: "gzip",
}),
];
HTML 文件中代码的压缩
我们之前使用了 HtmlWebpackPlugin 插件来生成 HTML 的模板,事实上它还有一些其他的配置
inject:设置打包的资源插入的位置
- true、 false 、body、head
cache:设置为 true,只有当文件改变时,才会生成新的文件(默认值也是 true)
minify:默认会使用一个插件 html-minifier-terser
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28const HtmlWebpackPlugin = require("html-webpack-plugin");
plugins: [
new HtmlWebpackPlugin({
template: "./index.html",
cache: true,
minify: isProdution
? {
// 移除注释
removeComments: true,
// 移除属性
removeEmptyAttributes: true,
// 移除默认属性
removeRedundantAttributes: true,
// 折叠空白字符
collapseWhitespace: true,
// 压缩内联的CSS
minifyCSS: true,
// 压缩JavaScript
minifyJS: {
mangle: {
toplevel: true,
},
},
}
: false,
}),
];
打包的时间分析
如果我们希望看到每一个 loader、每一个 Plugin 消耗的打包时间,可以借助于一个插件:speed-measure-webpack-plugin
- 注意:该插件在最新的 webpack 版本中存在一些兼容性的问题(和部分 Plugin 不兼容)
- 截止 2021-3-10 日,但是目前该插件还在维护,所以可以等待后续是否更新
- 我这里暂时的做法是把不兼容的插件先删除掉,也就是不兼容的插件不显示它的打包时间就可以了
第一步,安装 speed-measure-webpack-plugin 插件
1
npm install speed-measure-webpack-plugin -D
第二步,使用 speed-measure-webpack-plugin 插件
- 创建插件导出的对象 SpeedMeasurePlugin
- 使用 smp.wrap 包裹我们导出的 webpack 配置
1
2
3
4const SpeedMeasurePlugin = require("speed-measure-webpack-plugin");
const smp = new SpeedMeasurePlugin();
module.exports = smp.wrap({});
打包后文件分析
方案一:生成一个 stats.json 的文件
1
"build": "webpack --profile --json=stats.json",
通过执行 npm run build 可以获取到一个 stats.json 的文件
- 这个文件我们自己分析不容易看到其中的信息
- 可以放到 http://webpack.github.com/analyse,进行分析
方案二:使用 webpack-bundle-analyzer 工具
- 另一个非常直观查看包大小的工具是 webpack-bundle-analyzer
第一步,我们可以直接安装这个工具
1
npm install webpack-bundle-analyzer -D
第二步,我们可以在 webpack 配置中使用该插件
1
2
3
4
5const { BundleAnalyzerPlugin } = require("webpack-bundle-analyzer");
module.exports = {
plugins: [new BundleAnalyzerPlugin()],
};在打包 webpack 的时候,这个工具是帮助我们打开一个 8888 端口上的服务,我们可以直接的看到每个包的大小
- 比如有一个包时通过一个 Vue 组件打包的,但是非常的大,那么我们可以考虑是否可以拆分出多个组件,并且对其进行懒加载
- 比如一个图片或者字体文件特别大,是否可以对其进行压缩或者其他的优化处理
自定义 Loader
创建自己的 Loader
Loader 是用于对模块的源代码进行转换(处理),之前我们已经使用过很多 Loader,比如 css-loader、style-loader、babelloader 等
这里我们来学习如何自定义自己的 Loader
- Loader 本质上是一个导出为函数的 JavaScript 模块
- loader runner 库会调用这个函数,然后将上一个 loader 产生的结果或者资源文件传入进去
编写一个 my-loader-1.js 模块这个函数会接收三个参数
- content:资源文件的内容
- map:sourcemap 相关的数据
- meta:一些元数据
1
2
3
4module.exports = function (content, map, meta) {
console.log("my-loader-1:", content);
return content;
};在加载某个模块时,引入 loader
1
2
3
4
5
6
7
8
9
10
11
12
13
14const path = require("path");
module.exports = {
mode: "development",
entry: "./src/main.js",
output: {
path: path.resolve(__dirname, "./build"),
filename: "bundle.js",
},
resolveLoader: { modules: ["node_modules", "./my-loaders"] },
module: {
rules: [{ test: /\.js$/, use: ["my-loader-1"] }],
},
};
loader 的执行顺序
创建多个 Loader 使用,它的执行顺序是什么呢?
- 从后向前、从右向左的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// my-loaders/my-loader-1.js
module.exports = function (content, map, meta) {
console.log("my-loader-1:", content);
return content;
};
// my-loaders/my-loader-2.js
module.exports = function (content, map, meta) {
console.log("my-loader-2:", content);
return content;
};
// my-loaders/my-loader-3.js
module.exports = function (content, map, meta) {
console.log("my-loader-3:", content);
return content;
};
rules: [
{ test: /\.js$/, use: ["my-loader-1", "my-loader-2", "my-loader-3"] },
],事实上还有另一种 Loader,称之为 PitchLoader
1
2
3module.exports.pitch = function () {
console.log("loader pitch 1");
};
执行顺序和 enforce
其实这也是为什么 loader 的执行顺序是相反的
- run-loader 先优先执行 PitchLoader,在执行 PitchLoader 时进行 loaderIndex++
- run-loader 之后会执行 NormalLoader,在执行 NormalLoader 时进行 loaderIndex–
那么,能不能改变它们的执行顺序呢?
- 我们可以拆分成多个 Rule 对象,通过 enforce 来改变它们的顺序
enforce 一共有四种方式
- 默认所有的 loader 都是 normal
- 在行内设置的 loader 是 inline(import ‘loader1!loader2!./test.js’)
- 也可以通过 enforce 设置 pre 和 post
在 Pitching 和 Normal 它们的执行顺序分别是
- post, inline, normal, pre
- pre, normal, inline, post
1
2
3
4
5rules: [
{ test: /\.js$/, use: "my-loader-1" },
{ test: /\.js$/, use: "my-loader-2", enforce: "post" },
{ test: /\.js$/, use: "my-loader-3" },
],
同步的 Loader
什么是同步的 Loader 呢?
- 默认创建的 Loader 就是同步的 Loader
- 这个 Loader 必须通过 return 或者 this.callback 来返回结果,交给下一个 loader 来处理
- 通常在有错误的情况下,我们会使用 this.callback
this.callback 的用法如下
- 第一个参数必须是 Error 或者 null
- 第二个参数是一个 string 或者 Buffer
1
2
3
4
5
6module.exports = function (content, map, meta) {
console.log("my-loader-1:", content);
// 参数一: 错误信息
// 参数二: 传递给下一个 loader 的内容
this.callback(null, content);
};
异步的 Loader
什么是异步的 Loader 呢?
- 有时候我们使用 Loader 时会进行一些异步的操作
- 我们希望在异步操作完成后,再返回这个 loader 处理的结果
- 这个时候我们就要使用异步的 Loader 了
loader-runner 已经在执行 loader 时给我们提供了方法,让 loader 变成一个异步的 loader
1
2
3
4
5module.exports = function (content) {
setTimeout(() => {
this.async(null, content + "aaa");
}, 2000);
};
传入和获取参数
在使用 loader 时,传入参数
我们可以通过一个 webpack 官方提供的一个解析库 loader-utils,安装对应的库
1
npm install loader-utils -D
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16module.exports = function (content) {
// 1.获取使用 loader 时, 传递进来的参数
// 方式一: 早期时, 需要单独使用 loader-utils(webpack开发) 的库来获取参数
// 方式二: 目前, 已经可以直接通过 this.getOptions() 直接获取到参数
const options = this.getOptions();
console.log(options);
return content;
};
rules: [
{
test: /\.js$/,
use: [{ loader: "my-loader-3", options: { name: "strive", age: 20 } }],
},
],
校验参数
我们可以通过一个 webpack 官方提供的校验库 schema-utils,安装对应的库
1
npm install schema-utils -D
1
2
3
4
5
6
7
8
9
10{
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "请输入名称, 并且是string类型"
},
"age": { "type": "number", "description": "请输入年龄, 并且是number类型" }
}
}1
2
3
4
5
6
7
8
9
10
11const { validate } = require("schema-utils");
const loaderSchema = require("./schema/loader-schema.json");
module.exports = function (content) {
const options = this.getOptions();
console.log(options);
validate(loaderSchema, options);
return content;
};
babel-loader 案例
我们知道 babel-loader 可以帮助我们对 JavaScript 的代码进行转换,这里我们定义一个自己的 babel-loader
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21const babel = require("@babel/core");
module.exports = function (content) {
// 1.使用异步loader
const callback = this.async();
// 2.获取options
let options = this.getOptions();
if (!Object.keys(options).length) {
options = require("../babel.config");
}
// 使用Babel转换代码
babel.transform(content, options, (err, result) => {
if (err) {
callback(err);
} else {
callback(null, result.code);
}
});
};1
{ test: /\.js$/, use: { loader: "my-babel-loader" } },
自定义 Plugin
Webpack 和 Tapabl
- 我们知道 webpack 有两个非常重要的类:Compiler 和 Compilation
- 他们通过注入插件的方式,来监听 webpack 的所有生命周期
- 插件的注入离不开各种各样的 Hook,而他们的 Hook 是如何得到的呢?
- 其实是创建了 Tapable 库中的各种 Hook 的实例
- 所以,如果我们想要学习自定义插件,最好先了解一个库:Tapable
- Tapable 是官方编写和维护的一个库
- Tapable 是管理着需要的 Hook,这些 Hook 可以被应用到我们的插件中
Tapable 的 Hook 分类
- 同步和异步的
- 以sync开头的,是同步的 Hook
- 以async开头的,两个事件处理回调,不会等待上一次处理回调结束后再执行下一次回调
- 其他的类别
- Bail:当有返回值时,就不会执行后续的事件触发了
- Loop:当返回值为 true,就会反复执行该事件,当返回值为 undefined 或者不返回内容,就退出事件
- Waterfall:当返回值不为 undefined 时,会将这次返回的结果作为下次事件的第一个参数
- Parallel:并行,不会等到上一个事件回调执行结束,才执行下一次事件处理回调
- Series:串行,会等待上一是异步的 Hook
Hook 的使用过程
sync_基本使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24const { SyncHook } = require("tapable");
class MyCompiler {
constructor() {
// 第一步:创建Hook对象
this.hooks = {
syncHook: new SyncHook(["name", "age"]),
};
// 第二步:注册Hook中的事件
this.hooks.syncHook.tap("event1", (name, age) => {
console.log("event1事件监听执行了:", name, age);
});
this.hooks.syncHook.tap("event2", (name, age) => {
console.log("event2事件监听执行了:", name, age);
});
}
}
const compiler = new MyCompiler();
// 第三步:触发事件
setTimeout(() => {
compiler.hooks.syncHook.call("strive", 18);
}, 2000);sync_Bail 使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24const { SyncBailHook } = require("tapable");
class MyCompiler {
constructor() {
this.hooks = {
bailHook: new SyncBailHook(["name", "age"]),
};
this.hooks.bailHook.tap("event1", (name, age) => {
console.log("event1事件监听执行了:", name, age);
return 123;
});
this.hooks.bailHook.tap("event2", (name, age) => {
console.log("event2事件监听执行了:", name, age);
});
}
}
const compiler = new MyCompiler();
setTimeout(() => {
compiler.hooks.bailHook.call("strive", 18);
}, 2000);sync_Loop 使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29const { SyncLoopHook } = require("tapable");
let count = 0;
class MyCompiler {
constructor() {
this.hooks = {
loopHook: new SyncLoopHook(["name", "age"]),
};
this.hooks.loopHook.tap("event1", (name, age) => {
if (count < 5) {
console.log("event1事件监听执行了:", name, age);
count++;
return true;
}
});
this.hooks.loopHook.tap("event2", (name, age) => {
console.log("event2事件监听执行了:", name, age);
});
}
}
const compiler = new MyCompiler();
setTimeout(() => {
compiler.hooks.loopHook.call("strive", 18);
}, 2000);sync_waterfall 使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25const { SyncWaterfallHook } = require("tapable");
class MyCompiler {
constructor() {
this.hooks = {
waterfallHook: new SyncWaterfallHook(["name", "age"]),
};
this.hooks.waterfallHook.tap("event1", (name, age) => {
console.log("event1事件监听执行了:", name, age);
return { xx: "xx", yy: "yy" };
});
this.hooks.waterfallHook.tap("event2", (name, age) => {
console.log("event2事件监听执行了:", name, age);
});
}
}
const compiler = new MyCompiler();
setTimeout(() => {
compiler.hooks.waterfallHook.call("strive", 18);
}, 2000);async_parallel 使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27const { AsyncParallelHook } = require("tapable");
class MyCompiler {
constructor() {
this.hooks = {
parallelHook: new AsyncParallelHook(["name", "age"]),
};
this.hooks.parallelHook.tapAsync("event1", (name, age) => {
setTimeout(() => {
console.log("event1事件监听执行了:", name, age);
}, 3000);
});
this.hooks.parallelHook.tapAsync("event2", (name, age) => {
setTimeout(() => {
console.log("event2事件监听执行了:", name, age);
}, 3000);
});
}
}
const compiler = new MyCompiler();
setTimeout(() => {
compiler.hooks.parallelHook.callAsync("strive", 18);
}, 0);async_series 使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31const { AsyncSeriesHook } = require("tapable");
class MyCompiler {
constructor() {
this.hooks = {
seriesHook: new AsyncSeriesHook(["name", "age"]),
};
this.hooks.seriesHook.tapAsync("event1", (name, age, callback) => {
setTimeout(() => {
console.log("event1事件监听执行了:", name, age);
callback();
}, 3000);
});
this.hooks.seriesHook.tapAsync("event2", (name, age, callback) => {
setTimeout(() => {
console.log("event2事件监听执行了:", name, age);
callback();
}, 3000);
});
}
}
const compiler = new MyCompiler();
setTimeout(() => {
compiler.hooks.seriesHook.callAsync("strive", 18, () => {
console.log("所有任务都执行完成~");
});
}, 0);
自定义 Plugin
- 在之前的学习中,我们已经使用了非常多的 Plugin
- HTMLWebpackPlugin
- MiniCSSExtractPlugin
- CompressionPlugin
- 等等
- 这些 Plugin 是如何被注册到 webpack 的生命周期中的呢?
- 第一:在 webpack 函数的 createCompiler 方法中,注册了所有的插件
- 第二:在注册插件时,会调用插件函数或者插件对象的 apply 方法
- 第三:插件方法会接收 compiler 对象,我们可以通过 compiler 对象来注册 Hook 的事件
- 第四:某些插件也会传入一个 compilation 的对象,我们也可以监听 compilation 的 Hook 事件
开发自己的插件
如何开发自己的插件呢?
- 目前大部分插件都可以在社区中找到,但是推荐尽量使用在维护,并且经过社区验证的
- 这里我们开发一个自己的插件:将静态文件自动上传服务器中
自定义插件的过程
- 创建 AutoUploadWebpackPlugin 类
- 编写 apply 方法
- 通过 ssh 连接服务器
- 删除服务器原来的文件夹
- 上传文件夹中的内容
- 在 webpack 的 plugins 中,使用 AutoUploadWebpackPlugin 类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58const { NodeSSH } = require("node-ssh");
class AutoUploadWebpackPlugin {
constructor(options) {
this.ssh = new NodeSSH();
this.options = options;
}
apply(compiler) {
// 完成的事情: 注册hooks监听事件
// 等到assets已经输出到output目录上时, 完成自动上传的功能
compiler.hooks.afterEmit.tapAsync(
"AutoPlugin",
async (compilation, callback) => {
// 1.获取输出文件夹路径(其中资源)
const outputPath = compilation.outputOptions.path;
// 2.连接远程服务器 SSH
await this.connectServer();
// 3.删除原有的文件夹中内容
const remotePath = this.options.remotePath;
this.ssh.execCommand(`rm -rf ${remotePath}/*`);
// 4.将文件夹中资源上传到服务器中
await this.uploadFiles(outputPath, remotePath);
// 5.关闭ssh连接
this.ssh.dispose();
// 完成所有的操作后, 调用callback()
callback();
}
);
}
async connectServer() {
await this.ssh.connect({
host: this.options.host,
username: this.options.username,
password: this.options.password,
});
console.log("服务器连接成功");
}
async uploadFiles(localPath, remotePath) {
const status = await this.ssh.putDirectory(localPath, remotePath, {
recursive: true,
concurrency: 10,
});
if (status) {
console.log("文件上传服务器成功");
}
}
}
module.exports = AutoUploadWebpackPlugin;
module.exports.AutoUploadWebpackPlugin = AutoUploadWebpackPlugin;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20const path = require("path");
const HtmlWebpackPlugin = require("html-webpack-plugin");
const AutoUploadWebpackPlugin = require("./plugins/AutoUploadWebpackPlugin");
module.exports = {
entry: "./src/main.js",
output: {
path: path.resolve(__dirname, "./build"),
filename: "bundle.js",
},
plugins: [
new HtmlWebpackPlugin(),
new AutoUploadWebpackPlugin({
host: "111.222.33.44",
username: "root",
password: "1234",
remotePath: "/root/test",
}),
],
};
Gulp
- 什么是 Gulp?
- A toolkit to automate & enhance your workflow
- 一个工具包,可以帮你自动化和增加你的工作流
Gulp 和 Webpack 区别
- gulp 的核心理念是 task runner
- 可以定义自己的一系列任务,等待任务被执行
- 基于文件 Stream的构建流
- 我们可以使用 gulp 的插件体系来完成某些任务
- webpack 的核心理念是 module bundler
- webpack 是一个模块化的打包工具
- 可以使用各种各样的loader 来加载不同的模块
- 可以使用各种各样的插件在webpack 打包的生命周期完成其他的任务
- gulp 相对于 webpack 的优缺点
- gulp 相对于 webpack 思想更加的简单、易用,更适合编写一些自动化的任务
- 但是目前对于大型项目(Vue、React、Angular)并不会使用 gulp 来构建,比如默认 gulp 是不支持模块化的
Gulp 的基本使用
首先,我们需要安装 gulp
1
2
3
4# 全局安装
npm install gulp -g
# 局部安装
npm install gulp其次,编写 gulpfile.js 文件,在其中创建一个任务
1
2
3
4exports.foo = function (callback) {
console.log("第一个gulp任务");
callback();
};最后,执行 gulp 命令
1
npx gulp foo
创建 gulp 任务
每个 gulp 任务都是一个异步的 JavaScript 函数
- 此函数可以接受一个 callback 作为参数,调用 callback 函数那么任务会结束
- 或者是一个返回 stream、promise、event emitter、child process 或 observable 类型的函数
任务可以是 public 或者 private 类型的
- 公开任务(Public tasks) 从 gulpfile 中被导出(export),可以通过 gulp 命令直接调用
- 私有任务(Private tasks) 被设计为在内部使用,通常作为 series() 或 parallel() 组合的组成部分
补充:gulp4 之前, 注册任务时通过 gulp.task 的方式进行注册的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24const gulp = require("gulp");
// 编写异步的gulp任务
const bar = (callback) => {
setTimeout(() => {
console.log("bar任务被执行");
callback();
}, 2000);
};
// 早期编写任务的方式(gulp4.x之前)
gulp.task("baz", (callback) => {
console.log("baz任务被执行");
callback();
});
// 默认任务 npx gulp
module.exports.default = (callback) => {
console.log("default task exec");
callback();
};
// 导出的任务
module.exports = { bar };
任务组合 series 和 parallel
通常一个函数中能完成的任务是有限的(放到一个函数中也不方便代码的维护),所以我们会将任务进行组合
gulp 提供了两个强大的组合方法
- series():串行任务组合
- parallel():并行任务组合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27const { series, parallel } = require("gulp");
const foo1 = (cb) => {
setTimeout(() => {
console.log("foo1 task exec");
cb();
}, 2000);
};
const foo2 = (cb) => {
setTimeout(() => {
console.log("foo2 task exec");
cb();
}, 1000);
};
const foo3 = (cb) => {
setTimeout(() => {
console.log("foo3 task exec");
cb();
}, 3000);
};
const seriesFoo = series(foo1, foo2, foo3); // 按顺序依次执行
const parallelFoo = parallel(foo1, foo2, foo3); // 谁快就先执行谁
module.exports = { seriesFoo, parallelFoo };
读取和写入文件
gulp 暴露了 src() 和 dest() 方法用于处理计算机上存放的文件
- src() 接受参数,并从文件系统中读取文件然后生成一个Node 流(Stream),它将所有匹配的文件读取到内存中并通过流(Stream)进行处理
- 由 src() 产生的流(stream)应当从任务(task 函数)中返回并发出异步完成的信号
- dest() 接受一个输出目录作为参数,并且它还会产生一个 Node 流(stream),通过该流将内容输出到文件中
流(stream)所提供的主要的 API 是 .pipe() 方法,pipe 方法的原理是什么呢?
- pipe 方法接受一个 转换流(Transform streams)或可写流(Writable streams)
- 那么转换流或者可写流,拿到数据之后可以对数据进行处理,再次传递给下一个转换流或者可写流
1
2
3
4
5
6
7
8
9const { src, dest } = require("gulp");
const copyFile = () => {
// 1.读取文件
// 2.写入文件
return src("./src/**/*.js").pipe(dest("./dist"));
};
module.exports = { copyFile };
对文件进行转换
如果在这个过程中,我们希望对文件进行某些处理,可以使用社区给我们提供的插件
- 比如我们希望 ES6 转换成 ES5,那么可以使用 babel 插件
- 如果我们希望对代码进行压缩和丑化,那么可以使用 uglify 或者 terser 插件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17const { src, dest, watch } = require("gulp");
const babel = require("gulp-babel");
const terser = require("gulp-terser");
const task = () => {
return src("./src/**/*.js")
.pipe(babel({ presets: ["@babel/preset-env"] }))
.pipe(terser({ mangle: { toplevel: true } }))
.pipe(dest("./dist"));
};
// watch() 函数监听内容的改变
// watch() 函数利用文件系统的监控程序(file system watcher)将 与进行关联
watch("./src/**/*.js", jsTask);
module.exports = { task };
glob 文件匹配
- src() 方法接受一个 glob 字符串或由多个 glob 字符串组成的数组作为参数,用于确定哪些文件需要被操作
- glob 或 glob 数组必须至少匹配到一个匹配项,否则 src() 将报错
- glob 的匹配规则如下
- (一个星号*):在一个字符串中,匹配任意数量的字符,包括零个匹配
- (两个星号**):在多个字符串匹配中匹配任意数量的字符串,通常用在匹配目录下的文件
- (取反!)
- 由于 glob 匹配时是按照每个 glob 在数组中的位置依次进行匹配操作的
- 所以 glob 数组中的取反(negative)glob 必须跟在一个非取反(non-negative)的 glob 后面
- 第一个 glob 匹配到一组匹配项,然后后面的取反 glob 删除这些匹配项中的一部分
['script/**/*.js','!scripts/vendor/']
Gulp 案例
接下来,我们编写一个案例,通过 gulp 来开启本地服务和打包
- 打包 html 文件
- 使用 gulp-htmlmin 插件
- 打包 JavaScript 文件
- 使用 gulp-babel,gulp-terser 插件
- 打包 less 文件
- 使用 gulp-less 插件
- html 资源注入
- 使用 gulp-inject 插件
- 开启本地服务器
- 使用 browser-sync 插件
- 创建打包任务
- 创建开发任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60const { src, dest, parallel, series, watch } = require("gulp");
const htmlmin = require("gulp-htmlmin");
const babel = require("gulp-babel");
const terser = require("gulp-terser");
const less = require("gulp-less");
const inject = require("gulp-inject");
const browserSync = require("browser-sync");
// 1.对html进行打包
const htmlTask = () => {
return src("./src/**/*.html")
.pipe(htmlmin({ collapseWhitespace: true }))
.pipe(dest("./dist"));
};
// 2.对JavaScript进行打包
const jsTask = () => {
return src("./src/**/*.js")
.pipe(babel({ presets: ["@babel/preset-env"] }))
.pipe(terser({ toplevel: true }))
.pipe(dest("./dist"));
};
// 3.对less进行打包
const lessTask = () => {
return src("./src/**/*.less").pipe(less()).pipe(dest("./dist"));
};
// 4.在html中注入js和css
const injectTask = () => {
return src("./dist/**/*.html")
.pipe(
inject(src(["./dist/**/*.js", "./dist/**/*.css"]), { relative: true })
)
.pipe(dest("./dist"));
};
// 5.开启一个本地服务器
const bs = browserSync.create();
const serve = () => {
watch("./src/**", buildTask);
bs.init({
port: 8080,
open: true,
files: "./dist/*",
server: {
baseDir: "./dist",
},
});
};
// 创建项目构建的任务
const buildTask = series(parallel(htmlTask, jsTask, lessTask), injectTask);
const serveTask = series(buildTask, serve);
// webpack搭建本地 webpack-dev-server
module.exports = { buildTask, serveTask };- 打包 html 文件
Rollup
- 我们来看一下官方对 rollup 的定义
- Rollup is a module bundler for JavaScript which compiles small pieces of code into something larger and more complex, such as a library or application.
- Rollup 是一个JavaScript 的模块化打包工具,可以帮助我们编译小的代码到一个大的、复杂的代码中,比如一个库或者一个应用程序
- 我们会发现 Rollup 的定义、定位和 webpack 非常的相似
- Rollup 也是一个模块化的打包工具,但是 Rollup主要是针对 ES Module 进行打包的
- 另外 webpack 通常可以通过各种 loader 处理各种各样的文件,以及处理它们的依赖关系
- rollup 更多时候是专注于处理 JavaScript 代码的(当然也可以处理 css、font、v-ue 等文件)
- 另外 rollup 的配置和理念相对于 webpack 来说,更加的简洁和容易理解
- 在早期 webpack 不支持 tree shaking 时,rollup 具备更强的优势
- 目前 webpack 和 rollup 分别应用在什么场景呢?
- 通常在实际项目开发过程中,我们都会使用 webpack(比如 react、angular 项目都是基于 webpack 的)
- 在对库文件进行打包时,我们通常会使用 rollup(比如 vue、react、dayjs 源码本身都是基于 rollup 的,Vite 底层使用 Rollup)
Rollup 基本使用
我们可以先安装 rollup
1
2
3
4# 全局安装
npm install rollup -g
# 局部安装
npm install rollup -D创建 main.js 文件,打包到 bundle.js 文件中
1
2
3
4
5
6
7
8# 打包浏览器的库
npx rollup ./src/main.js -f iife -o dist/bundle.js
# 打包AMD的库
npx rollup ./src/main.js -f amd -o dist/bundle.js
# 打包CommonJS的库
npx rollup ./src/main.js -f cjs -o dist/bundle.js
# 打包通用的库(必须跟上name)
npx rollup ./src/main.js -f umd --name mathUtil -o dist/bundle.js
Rollup 的配置文件
我们可以将配置信息写到配置文件中 rollup.config.js 文件
1
2
3
4
5
6
7
8module.exports = {
input: "./lib/index.js",
output: {
format: "umd",
name: "mathUtil",
file: "./build/bundle.umd.js",
},
};我们可以对文件进行分别打包,打包出更多的库文件(用户可以根据不同的需求来引入)
1
2
3
4
5
6
7
8
9module.exports = {
input: "./lib/index.js",
output: [
{ format: "umd", name: "mathUtil", file: "./build/bundle.umd.js" },
{ format: "amd", file: "./build/bundle.amd.js" },
{ format: "cjs", file: "./build/bundle.cjs.js" },
{ format: "iife", name: "mathUtil", file: "./build/bundle.browser.js" },
],
};
解决 cjs 和第三方库问题
安装解决 commonjs 的库
1
npm install @rollup/plugin-commonjs -D
安装解决 node_modules 的库
1
npm install @rollup/plugin-node-resolve -D
打包和排除 lodash
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 默认 lodash 没有被打包是因为它使用 commonjs, rollup 默认情况下只会处理ES Module
const commonjs = require("@rollup/plugin-commonjs");
const nodeResolve = require("@rollup/plugin-node-resolve");
module.exports = {
input: "./lib/index.js",
output: {
format: "umd",
name: "mathUtil",
file: "./build/bundle.umd.js",
globals: { lodash: "_" },
},
external: ["lodash"],
plugins: [commonjs(), nodeResolve()],
};
Babel 转换代码
如果我们希望将 ES6 转成 ES5 的代码,可以在 rollup 中使用 babel
安装 rollup 对应的 babel 插件
1
npm install @rollup/plugin-babel -D
修改配置文件
- 需要配置 babel.config.js 文件
- babelHelpers
1
2
3
4
5
6
7
8
9
10
11
12const { babel } = require("@rollup/plugin-babel");
plugins: [
babel({
babelHelpers: "bundled",
exclude: "/node_modules/**",
}),
],
// babel.config.js
(module.exports = {
presets: [["@babel/preset-env"]],
});
Teser 代码压缩
如果我们希望对代码进行压缩,可以使用@rollup/plugin-terser
1
npm install @rollup/plugin-terser -D
配置 terser
1
2
3const terser = require("@rollup/plugin-terser");
plugins: [terser()];
处理 css 文件
如果我们项目中需要处理 css 文件,可以使用 postcss
1
npm install rollup-plugin-postcss postcss -D
配置 postcss 的插件
1
2
3const postcss = require("rollup-plugin-postcss");
plugins: [postcss()];
处理 vue 文件
处理 vue 文件我们需要使用 rollup-plugin-vue 插件
- 但是注意:默认情况下我们安装的是 vue3.x 的版本
1
npm install rollup-plugin-vue @vue/compiler-sfc -D
使用 vue 的插件
1
2
3const vue = require("rollup-plugin-vue");
plugins: [vue()];
打包 vue 报错
在我们打包 vue 项目后,运行会报如下的错误
- ReferenceError: process is not defined
这是因为在我们打包的 vue 代码中,用到 process.env.NODE_ENV,所以我们可以使用一个插件 rollup-plugin-replace 设置它对应的值
1
npm install @rollup/plugin-replace -D
配置插件信息
1
2
3
4
5
6
7
8const replace = require("@rollup/plugin-replace");
plugins: [
replace({
"process.env.NODE_ENV": JSON.stringify("production"),
preventAssignment: true,
}),
];
搭建本地服务器
第一步:使用 rollup-plugin-serve 搭建服务
1
npm install rollup-plugin-serve -D
1
2
3const serve = require("rollup-plugin-serve");
plugins: [serve({ port: 8000, open: true, contentBase: "." })];第二步:当文件发生变化时,自动刷新浏览器
1
npm install rollup-plugin-livereload -D
1
2
3const livereload = require("rollup-plugin-livereload");
plugins: [livereload()];第三步:启动时,开启文件监听
1
npx rollup -c -w
区分开发环境
我们可以在 package.json 中创建一个开发和构建的脚本
1
2
3
4"scripts": {
"build": "rollup -c --environment NODE_ENV:production",
"serve": "rollup -c --environment NODE_ENV:development -w"
}1
2
3
4
5
6
7
8
9
10
11
12
13const isProduction = process.env.NODE_ENV === "production";
const plugins = [];
if (isProduction) {
plugins.push("生产环境的插件");
} else {
plugins.push("开发环境的插件");
}
module.exports = {
// ...
plugins: plugins,
};
vite
- 什么是 vite 呢?
- 官方的定位:下一代前端开发与构建工具
- 如何定义下一代开发和构建工具呢?
- 我们知道在实际开发中,我们编写的代码往往是不能被浏览器直接识别的,比如 ES6、TypeScript、Vue 文件等等
- 所以我们必须通过构建工具来对代码进行转换、编译,类似的工具有 webpack、rollup、parcel
- 但是随着项目越来越大,需要处理的 JavaScript 呈指数级增长,模块越来越多
- 构建工具需要很长的时间才能开启服务器,HMR 也需要几秒钟才能在浏览器反应出来
- 所以也有这样的说法:天下苦 webpack 久矣
- Vite (法语意为 “快速的”,发音 /vit/) 是一种新型前端构建工具,能够显著提升前端开发体验
Vite 的构造
- 它主要由两部分组成
- 一个开发服务器,它基于原生 ES 模块提供了丰富的内建功能,HMR 的速度非常快速
- 一套构建指令,它使用 rollup 打开我们的代码,并且它是预配置的,可以输出生成环境的优化过的静态资源
- 在浏览器支持 ES 模块之前,JavaScript 并没有提供原生机制让开发者以模块化的方式进行开发
- 这也正是我们对 “打包” 这个概念熟悉的原因:使用工具抓取、处理并将我们的源码模块串联成可以在浏览器中运行的文件
- 时过境迁,我们见证了诸如 webpack、Rollup 和 Parcel 等工具的变迁,它们极大地改善了前端开发者的开发体验
- 然而,当我们开始构建越来越大型的应用时,需要处理的 JavaScript 代码量也呈指数级增长。包含数千个模块的大型项目相当普遍
- 基于 JavaScript 开发的工具就会开始遇到性能瓶颈:通常需要很长时间(甚至是几分钟!)才能启动开发服务器,即使使用模块热替换(HMR),文件修改后的效果也需要几秒钟才能在浏览器中反映出来
- Vite 旨在利用生态系统中的新进展解决上述问题
- 浏览器开始原生支持 ES 模块,且越来越多 JavaScript 工具使用编译型语言编写
- the rise of JavaScript tools written in compile-to-native languages
浏览器原生支持模块化
但是如果我们不借助于其他工具,直接使用 ES Module 来开发有什么问题呢?
1
<script src="./src/main.js" type="module"></script>
1
import _ from "../node_modules/lodash-es/lodash.default.js"; // npm install lodash-es
- 首先,我们会发现在使用 loadash 时,加载了上百个模块的 js 代码,对于浏览器发送请求是巨大的消耗
- 其次,我们的代码中如果有 TypeScript、less、vue 等代码时,浏览器并不能直接识别
事实上,vite 就帮助我们解决了上面的所有问题
Vite 的安装
首先,我们安装一下 vite 工具
1
2
3npm install vite -g
npm install vite -D通过 vite 来启动项目
1
npx vite
Vite 对 css 的支持
vite 可以直接支持 css 的处理
- 直接导入 css 即可
vite 可以直接支持 css 预处理器,比如 less
- 直接导入 less
- 之后安装 less 编译器
1
npm install less -D
vite 直接支持 postcss 的转换
- 只需要安装 postcss,并且配置 postcss.config.js 的配置文件即可
1
npm install postcss postcss-preset-env -D
1
2
3
4// postcss.config.js
module.exports = {
plugins: [require("postcss-preset-env")],
};
Vite 对 TypeScript 的支持
- vite 对 TypeScript 是原生支持的,它会直接使用 ESBuild 来完成编译
- 只需要直接导入即可
- 如果我们查看浏览器中的请求,会发现请求的依然是 ts 的代码
- 这是因为 vite 中的服务器 Connect 会对我们的请求进行转发
- 获取 ts 编译后的代码,给浏览器返回,浏览器可以直接进行解析
- 注意:在 vite2 中,已经不再使用 Koa 了,而是使用 Connect 来搭建的服务器
Vite 对 vue 的支持
vite 对 vue 提供第一优先级支持
- Vue 3 单文件组件支持:@vitejs/plugin-vue
- Vue 3 JSX 支持:@vitejs/plugin-vue-jsx
- Vue 2 支持:underfin/vite-plugin-vue2
安装支持 vue 的插件
1
npm install @vitejs/plugin-vue -D
在 vite.config.js 中配置插件
1
2
3
4
5
6import { defineConfig } from "vite";
import vue from "@vitejs/plugin-vue";
export default defineConfig({
plugins: [vue()],
});
Vite 对 react 的支持
- .jsx 和 .tsx 文件同样开箱即用,它们也是通过 ESBuild 来完成的编译
- 所以我们只需要直接编写 react 的代码即可
- 注意:在 index.html 加载 main.js 时,我们需要将 main.js 的后缀,修改为 main.jsx 作为后缀名
Vite 打包项目
我们可以直接通过 vite build 来完成对当前项目的打包工具
1
npx vite build
我们可以通过 preview 的方式,开启一个本地服务来预览打包后的效果
1
npx vite preview
Vite 脚手架工具
在开发中,我们不可能所有的项目都使用 vite 从零去搭建,比如一个 react 项目、Vue 项目
- 这个时候 vite 还给我们提供了对应的脚手架工具
所以 Vite 实际上是有两个工具的
- vite:相当于是一个构件工具,类似于 webpack、rollup
- @vitejs/create-app:类似 vue-cli、create-react-app
如何使用脚手架工具呢?
1
2
3
4
5npm create vite
yarn create vite
pnpm create vite
ESBuild 解析
- ESBuild 的特点
- 超快的构建速度,并且不需要缓存
- 支持 ES6 和 CommonJS 的模块化
- 支持 ES6 的 Tree Shaking
- 支持 Go、JavaScript 的 API
- 支持 TypeScript、JSX 等语法编译
- 支持 SourceMap
- 支持代码压缩
- 支持扩展其他插件
ESBuild 的构建速度
ESBuild 的构建速度和其他构建工具速度对比
ESBuild 为什么这么快呢?
- 使用 Go 语言编写的,可以直接转换成机器代码,而无需经过字节码
- ESBuild 可以充分利用 CPU 的多内核,尽可能让它们饱和运行
- ESBuild 的所有内容都是从零开始编写的,而不是使用第三方,所以从一开始就可以考虑各种性能问题
- 等等
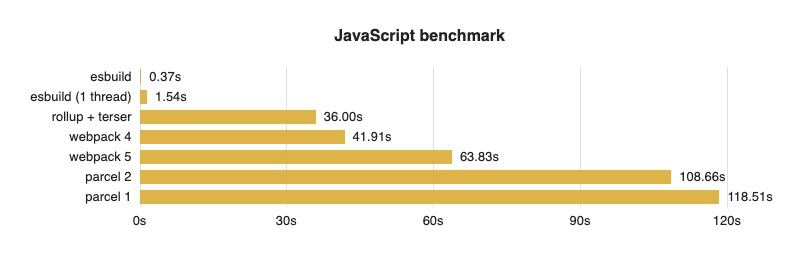
自定义脚手架
package.json
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17{
"name": "mycli",
"version": "1.0.1",
"description": "",
"main": "index.js",
"bin": {
"mycli": "./lib/index.js"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"commander": "^9.4.1",
"download-git-repo": "^3.0.2",
"ejs": "^3.1.8"
}
}- npm install
- npm link 软连接 加入到环境变量里
lib/template/component.vue.ejs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17<template>
<div class="<%= lowername %>">
<h2><%= name %>: {{ message }}</h2>
</div>
</template>
<script setup>
import { ref } from "vue";
const message = ref("哈哈哈");
</script>
<style>
.<%= lowername % > {
color: red;
}
</style>lib/index.js
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
const { program } = require("commander");
const { promisify } = require("util");
const download = promisify(require("download-git-repo"));
const { spawn } = require("child_process");
const fs = require("fs");
const path = require("path");
const ejs = require("ejs");
// 执行命令
function executeCommand(...args) {
return new Promise((resolve) => {
// npm install | npm run dev
// 1.开启子进程执行命令
const childProcess = spawn(...args);
// 2.获取子进程的输出和错误信息
childProcess.stdout.pipe(process.stdout);
childProcess.stderr.pipe(process.stderr);
// 3.监听子进程执行结束, 关闭掉
childProcess.on("close", () => {
resolve();
});
});
}
// 编译Ejs
function compileEjs(name, data) {
return new Promise((resolve, reject) => {
// 1.获取当前模板的路径
const tempPath = `./template/${name}`;
const absolutePath = path.resolve(__dirname, tempPath);
// 2.使用ejs引擎编译模板
ejs.renderFile(absolutePath, data, (err, result) => {
if (err) {
return reject(err);
}
resolve(result);
});
});
}
// 1.配置所有的 options
// 处理 --version 的操作
const version = require("../package.json").version;
program.version(version, "-v --version");
// 2.增强其他的 options 的操作
program.option("-pt --path <path>", "自定义路径");
program.option("-p", "src/page 指定路径");
program.option("-c", "src/component 指定路径");
program.on("--help", () => {
console.log("others");
console.log(" xxx");
console.log(" yyy");
});
// 2.增加具体的一些功能操作
program
.command("create <project> [...others]")
.description("创建 Vue/React 项目")
.action(async (project, others) => {
// mycli create 项目名称 其他参数
try {
// 1.从编写的项目模板中 clone 下来项目
await download(
"direct:https://github.com/coderwhy/vue3_template.git#main",
project,
{ clone: true }
);
// 2.很多的脚手架, 都是在这里给予提示
// console.log("cd ${project}")
// console.log("npm install")
// console.log("npm run dev")
// 3.帮助执行 npm install
const commandName = process.platform === "win32" ? "npm.cmd" : "npm";
const cwd = { cwd: `./${project}` };
await executeCommand(commandName, ["install"], cwd);
// 4.帮助执行 npm run dev
await executeCommand(commandName, ["run", "dev"], cwd);
} catch (error) {
console.log(error);
}
});
program
.command("add <name> [...others]")
.description("创建 页面/组件 文件")
.action(async (name, others) => {
// 1.编写组件的模板, 根据内容给模板中填充数据
const result = await compileEjs("component.vue.ejs", {
name,
lowername: name.toLowerCase(),
});
// 2.将 result 写入到对应的文件夹中
const { p, c, path } = program.opts();
let location = "";
if (p) {
location = "src/page";
} else if (c) {
location = "src/components";
} else if (path) {
location = path;
} else {
location = "src/components";
}
fs.promises
.writeFile(`${location}/${name}.vue`, result)
.then(() => {
console.log(`创建文件成功, 目录地址: ${location}`);
})
.catch((error) => {
if (error.errno === -4058) {
console.log(`当前路径有问题, 请检查路径是否正确: ${location}`);
}
});
});
// 让 commander 解析 process.argv 参数
program.parse(process.argv);
// 获取额外传递的参数
// console.log(program.opts())